OpenTelemetry
Opentelemetry 是一个CNCF社区下一个开源的可观测性框架,或者也可以说是一组工具、API 和 SDK 的集合,来检测、生成、收集和导出可观测性数据(指标、日志和链路),以帮助我们分析软件的性能和行为。
优点
过去,检测代码的方式会有所不同,因为每个可观测性后端都有自己的检测库和代理,用于向工具发送数据。
这意味着没有用于将数据发送到可观察性后端的标准化数据格式,由于缺乏标准化,最终结果是缺乏数据可移植性和用户维护仪器库的负担。
Opentelemetry因此而生,拥有来自云提供商、 供应商和最终用户的广泛行业支持和采用,提供了:
每种语言都有一个独立于供应商的instrumentation library ,支持自动和手动。
可以以多种方式部署的单个供应商中立的收集器二进制文件。
生成、发出、收集、处理和导出遥测数据的端到端实现。
完全控制您的数据,能够通过配置将数据并行发送到多个目的地。
开放标准语义约定以确保与供应商无关的数据收集
能够并行支持多种 上下文传播 格式,以协助随着标准的发展进行迁移。
缺点
有别于 Istio ,它并不是一个开箱即用的工具,也是更有侵入性的,但是根据我们的经验:
越不具侵入性的工具,就越无法做出更深更广的观测
我们为了获取更深、更广的指标,势必要侵入性地进行观测,因此,采用Istio envoy提供的指标是不够的。而此时,Opentelemetry正在逐渐形成行业标准,受到许多供应商支持,是我们一个很好的选择。
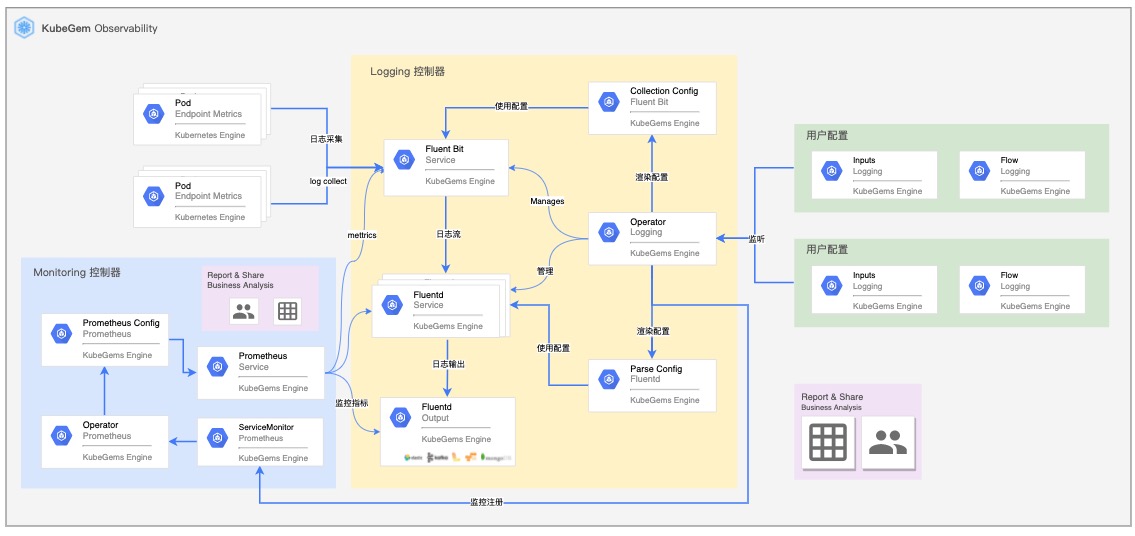
OpenTelemetry 架构
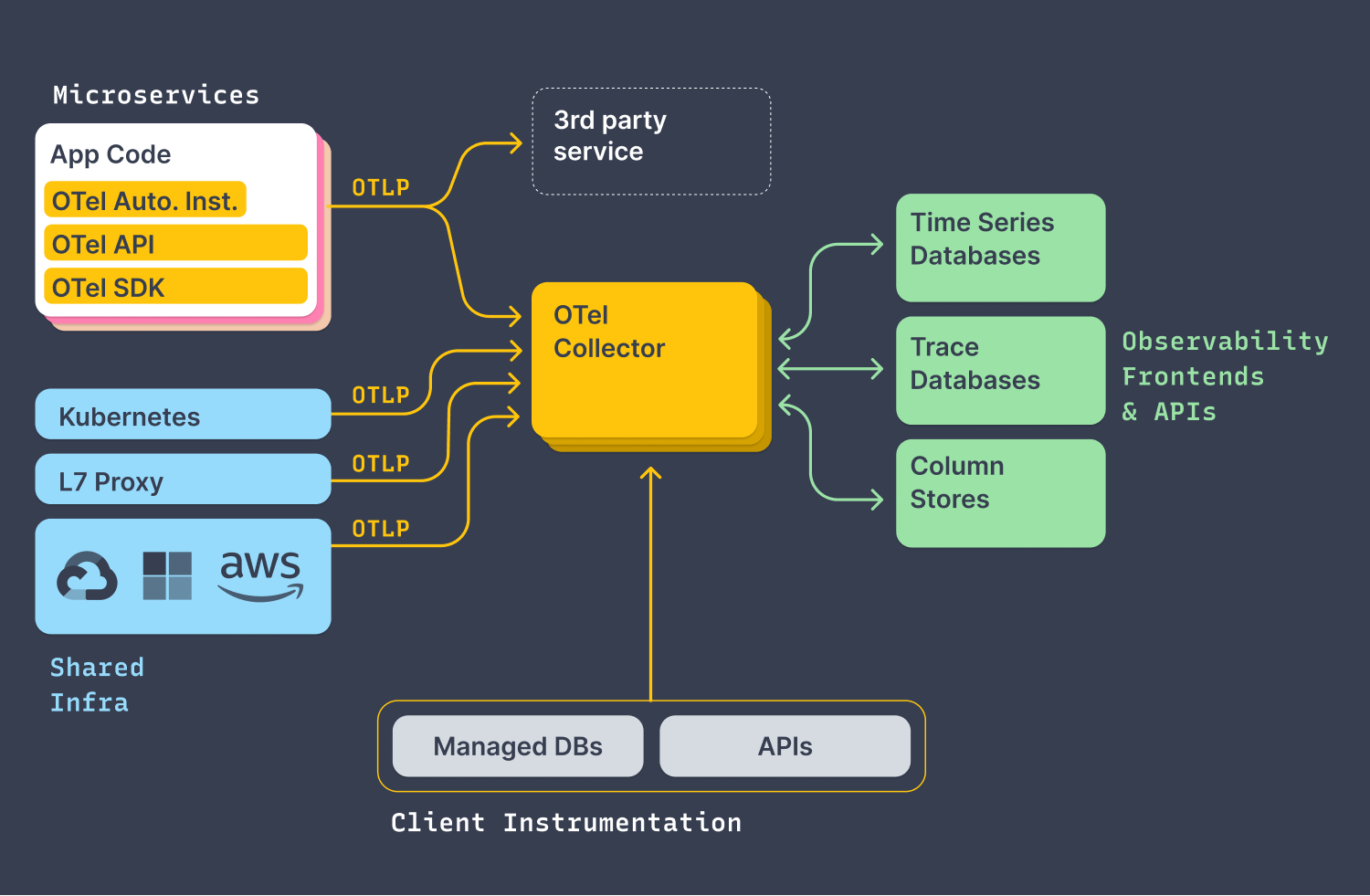
如上图所示,整体的组织架构实际可以理解为两部分:
- 将可观测性数据(trace, metric, log)全部导出(push)到
otel collector,无论你是通过什么形式,来自什么组件,如:
从项目代码通过
otlp协议导出- 语言:go, java, python...
- 集成方式: auto/manual instrumentation, api, sdk
# example config for otel collector's receivers
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
- 通过基础设施(本质上还是通过应用程序导出)
- k8s
- aws
- others...
- 通过其他服务,直接将一些服务数据导出到
otel collector,如- prometheus
- jarger
- others...
将不同类型的数据按需求导出(push or pull)到具体的可观测性工具,如
- metrics 指标可以导出至监控服务(如通过prometheues)
- trace 指标可以导出至链路追踪服务(如jaeger)
- log 指标可以导出至日志服务(如loki)
# example config for otel collector's exporters
exporters:
jaeger:
endpoint: jaeger-operator-jaeger-collector.observability:14250
tls:
insecure: true
loki:
endpoint: http://localhost:3100/loki/api/v1/push
prometheus:
endpoint: 0.0.0.0:8889
resource_to_telemetry_conversion:
enabled: true
项目组织结构
Opentelemetry项目组织结构繁多而复杂,官方共有59个repo,但我可以大致按以下结构进行梳理:
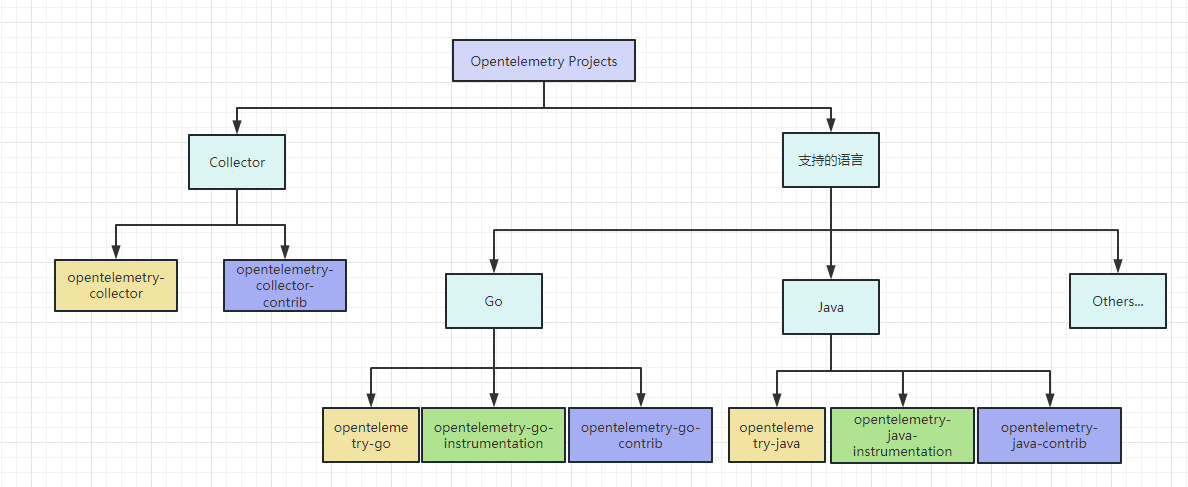
首先,Opentelemetry提供了官方的opentelemetry-collector,作为整个项目的核心仓库,用以整和所有可观测性指标,也整合了opentelemetry-collector-contrib提供的第三方服务,这两个项目统一构成collector,但是作为开发者,我们不需要过多关心。
然后,针对不同的语言,基本每种语言都提供了三个仓库作以下用途:
核心仓库(黄色): 提供该语言的基础SDK,为
instrumentation和contrib仓库提供接入的统一标准,通过这个仓库,你也可以在不使用以下两个库的情况下接入opentelemetry。instrumentation(绿色): 特定的语言实现,通过它,你可以在不甚了解otel的情况下,实现一体化、开箱即用地、一键地为你的工程引入opentelemetry。
如
opentelemetry-java-instrumentation可以直接以java -javaagent:path/to/opentelemetry-javaagent.jar \
-jar myapp.jar的形式接入opentelemetry。
contrib(蓝色): 提供一些为第三方库以相对便捷的形式接入Opentelemetry的库。
如
opentelemetry-go-contrib提供了针对gin,beego框架等第三方库接入opentelemetry的便捷方法。
Golang 实践指南
Trace(stable)
初始化
我们需要构造一个全局的TraceProvider,下面的例子构造的provider 采用的 http exporter,即将traces通过http协议发送给指定的opentelemetry-collector
import (
"context"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp"
"go.opentelemetry.io/otel/propagation"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
)
func initTracer(ctx context.Context) (*sdktrace.TracerProvider, error) {
exp, err := otlptracehttp.New(ctx)
if err != nil {
return nil, err
}
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()),
sdktrace.WithBatcher(exp),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.TraceContext{})
return tp, nil
}
注意:
- 全局
TraceProvider通过otel.SetTracerProvider()设置,获取时,也可直接调otel.GetTracerProvider()。
我建议大家直接设置为全局的,而不是作为局部变量传来传去的一个好处是,当我们引用了第三方库,它通常也会默认使用全局的provider,这样就能简单的保证我们一个程序只有一个provider,也就是说,只会把数据发送到一个collector。
- 初始化的过程中,不需要指定
opentelemetry-collector endpoint等配置,我们统一通过环境变量注入。如:
otlptracehttp.WithEndpoint()=>OTEL_EXPORTER_OTLP_ENDPOINTotlptracehttp.WithInsecure=>OTEL_EXPORTER_OTLP_INSECURE
支持的环境变量:
- 基础配置: https://opentelemetry.io/docs/concepts/sdk-configuration/general-sdk-configuration/
- 导出器: https://opentelemetry.io/docs/concepts/sdk-configuration/otlp-exporter-configuration/
采样器
Go SDK 提供了几个基本的采样器:
AlwaysSample(): 全部采样NeverSample(): 全部丢弃TraceIDRatioBased(fraction float64): 设置采样率ParentBased(root Sampler, samplers ...ParentBasedSamplerOption): 基于parent span 设置采样策略
除此之外,根据Sampler接口:
// Sampler decides whether a trace should be sampled and exported.
type Sampler interface {
// DO NOT CHANGE: any modification will not be backwards compatible and
// must never be done outside of a new major release.
// ShouldSample returns a SamplingResult based on a decision made from the
// passed parameters.
ShouldSample(parameters SamplingParameters) SamplingResult
// DO NOT CHANGE: any modification will not be backwards compatible and
// must never be done outside of a new major release.
// Description returns information describing the Sampler.
Description() string
// DO NOT CHANGE: any modification will not be backwards compatible and
// must never be done outside of a new major release.
}
我们可以编写自己的采样器,eg:
import (
"go.opentelemetry.io/otel"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
)
// kubegems sampler, ignore samples whitch contains "kubegems.ignore" attrbute.
type kubegemsSampler struct{}
func (as kubegemsSampler) ShouldSample(p sdktrace.SamplingParameters) sdktrace.SamplingResult {
result := sdktrace.SamplingResult{
Tracestate: trace.SpanContextFromContext(p.ParentContext).TraceState(),
}
shouldSample := true
for _, att := range p.Attributes {
if att.Key == "kubegems.ignore" && att.Value.AsBool() == true {
shouldSample = false
break
}
}
if shouldSample {
result.Decision = sdktrace.RecordAndSample
} else {
result.Decision = sdktrace.Drop
}
return result
}
func (as kubegemsSampler) Description() string {
return "KubegemsSampler"
}
使用采样器时,我们需要注意以下问题:
假如有两个服务为A,B, 调用关系为 A -> B, 我们想要为其设置采样率为50%,怎么设?
直接为两个服务都设置
sdktrace.WithSampler(sdktrace.TraceIDRatioBased(0.5))这样设置后,A的采样率自然是50%,但B的采样率并不会成了25%,测试发现它仍然是50%。我们可以查阅设计文档:
- The
TraceIdRatioBasedMUST ignore the parentSampledFlag. To respect the parentSampledFlag, theTraceIdRatioBasedshould be used as a delegate of theParentBasedsampler specified below.
也就是说,它只会根据parent span来决定是否被采样
- The
使用
ParentBased采样器(最好的方法)sdktrace.WithSampler(sdktrace.ParentBased(sdktrace.TraceIDRatioBased(0.5))),ParentBased Sampler显式地配置有parent span情况下地采样策略,默认情况下使用如下策略:func configureSamplersForParentBased(samplers []ParentBasedSamplerOption) samplerConfig {
c := samplerConfig{
remoteParentSampled: AlwaysSample(),
remoteParentNotSampled: NeverSample(),
localParentSampled: AlwaysSample(),
localParentNotSampled: NeverSample(),
}
for _, so := range samplers {
c = so.apply(c)
}
return c
}以
remoteParentSampled: AlwaysSample()为例:它是说,默认情况下,如果这个span来自远程的parent span,而且parent spane已经被采样了,那么,这个span也会被采样。我们也可以调整
ParentBasedSamplerOption参数,eg:sdktrace.WithSampler(sdktrace.ParentBased(sdktrace.TraceIDRatioBased(0.5), sdktrace.WithRemoteParentSampled(sdktrace.NeverSample()))),它表示,当
parent span被采样时,自己不采样,当然,这是不合理的。
埋点
我们可以在想要记录trace的地方,通过tracer.Start()创建一个新span来埋点。
当然,在span中,我可以主要可以添加以下几类信息:
SetAttributes: 设置一些属性(记录为tag)AddEvent: 添加事件(记录为log), 通常用来记录一些重要操作SetStatus: 设置span状态。
// get user name by user id
func getUser(ctx context.Context, id string) (string, error) {
// start a new span from context.
newCtx, span := tracer.Start(ctx, "getUser", trace.WithAttributes(attribute.String("user.id", id)))
defer span.End()
// add start event
span.AddEvent("start to get user",
trace.WithTimestamp(time.Now()),
)
var username string
// get user name from db, if you want to trace it, `WithContext` is necessary.
result := getDB().WithContext(newCtx).Raw(`select username from users where id = ?`, id).Scan(&username)
if result.Error != nil || result.RowsAffected == 0 {
err := fmt.Errorf("user %s not found", id)
span.SetStatus(codes.Error, err.Error())
return "", err
}
// set user info in span's attributes
span.SetAttributes(attribute.String("user.name", username))
// add end event
span.AddEvent("end to get user",
trace.WithTimestamp(time.Now()),
trace.WithAttributes(attribute.String("user.name", username)),
)
span.SetStatus(codes.Ok, "")
return username, nil
}
届时,span大概长这个样子:
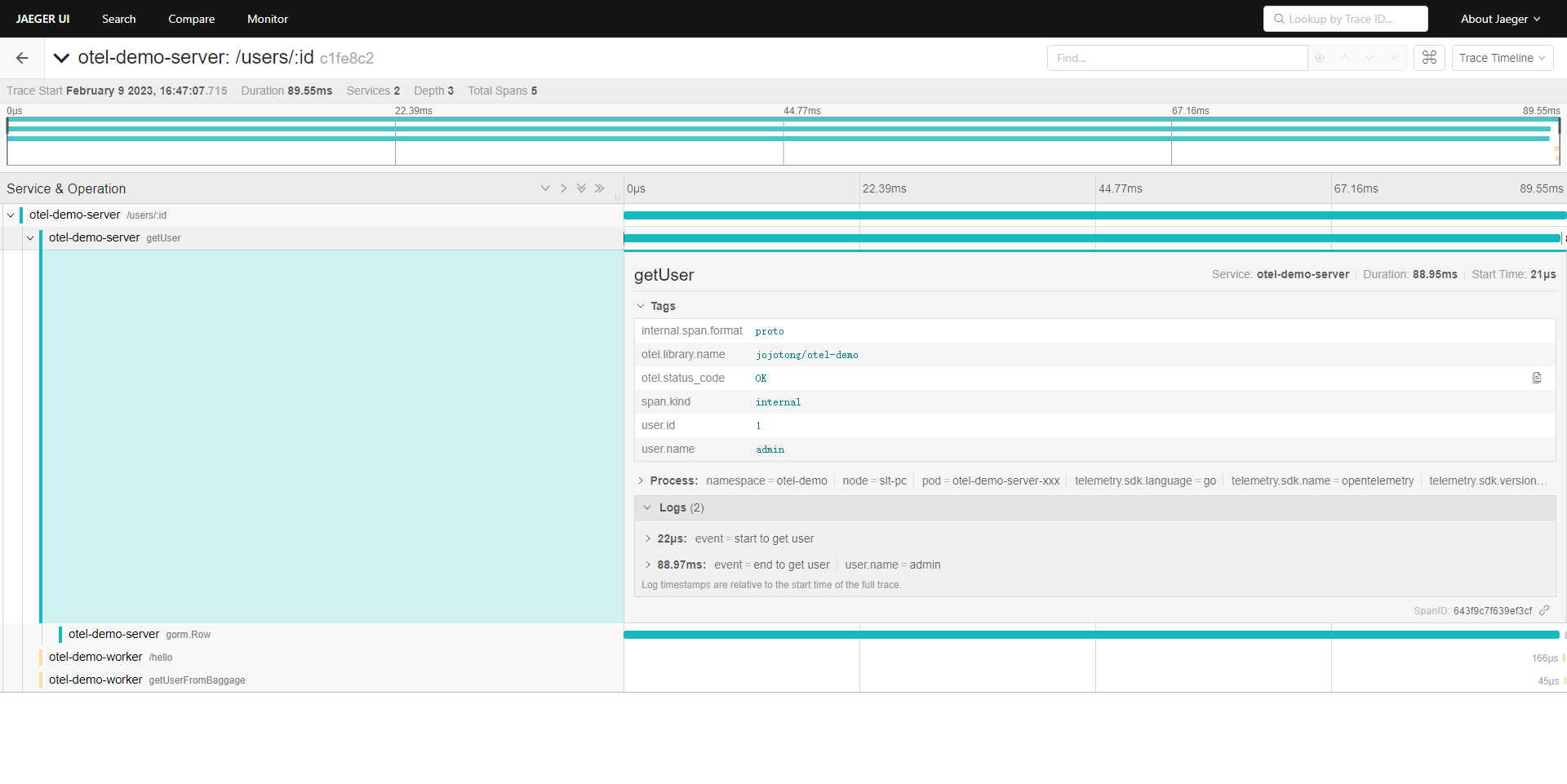
另外,关于span的父子关系,是通过context上下文来传递的。
在tracer.Start(ctx context.Context, ...)中,如果传入的ctx 中没有span,那么返回的就是root span;如果有,那返回的就是该span的子span。
因此,我们能通过context串联起清晰的链路调用,但也因此,我们需要非常关注context的使用。
跨进程传播
Openletemetry 提供 propagator在进程间交换的消息中读取和写入上下文数据的对象,详见 https://opentelemetry.io/docs/reference/specification/context/api-propagators/
Openletemetry 实现了两种propagator API:
TraceContext: 用以传播traceparent和tracestate信息来保证一条trace的调用信息不会因为跨进程而中断Baggage: 用以传播用户自定义信息
propagator实现两个方法:
Inject(ctx context.Context, carrier TextMapCarrier): Injects the value into a carrier. For example, into the headers of an HTTP request.Extract(ctx context.Context, carrier TextMapCarrier) context.Context: Extracts the value from an incoming request. For example, from the headers of an HTTP request.
TraceContext
使用TraceContext在下游Inject和上游Extract来打通服务间调用链路, eg:
- 设置propagater:
otel.SetTextMapPropagator(propagation.TraceContext{})
- client:
import (
"net/http"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/propagation"
)
func DoRequest(){
...
req, err := http.NewRequestWithContext(ctx, method, addr, body)
// inject to http.Request by propagator to do distribute tracing
otel.GetTextMapPropagator().Inject(req.Context(), propagation.HeaderCarrier(req.Header))
http.DefaultClient.Do(req)
...
}
- server:
import (
"go.opentelemetry.io/otel/propagation"
)
func HandleRequest(){
...
// extract from http.Request by propagator to do distribute tracing
ctx := cfg.Propagators.Extract(req.Context(), propagation.HeaderCarrier(req.Header))
ctx, span := tracer.Start(ctx, spanName, opts...)
defer span.End()
req = req.WithContext(ctx)
...
}
如果你想了解更多关于TraceContext的信息,可以阅读文档:https://www.w3.org/TR/trace-context/,因为它遵从`W3C Trace Context format`标准。
Baggage
使用Baggage在进程间传递信息,在使用它之前,我们需要弄清楚两个问题:
为什么我们需要 Baggage?
- 在整条trace中传播信息
- 假如我们希望将应用程序中的信息附加到一个 span, 并在稍后检索该信息,然后将其用于另一个 span。由于span一经创建就不能修改,而Baggage 允许通过提供一个存储和检索信息的地方来解决这个问题。
Baggage应该用来做什么?
Baggage 应该用于我们可以向第三方公开的非敏感数据,因为它与当前上下文一起存储在 HTTP 标头中。
建议用来传播包括帐户标识、用户 ID、产品 ID 和原始 IP 等内容。将它们向下传递之后,我们就可以将它们添加到下游服务中的 Span 中,以便在在可观察性后端中进行搜索时更轻松地进行过滤。
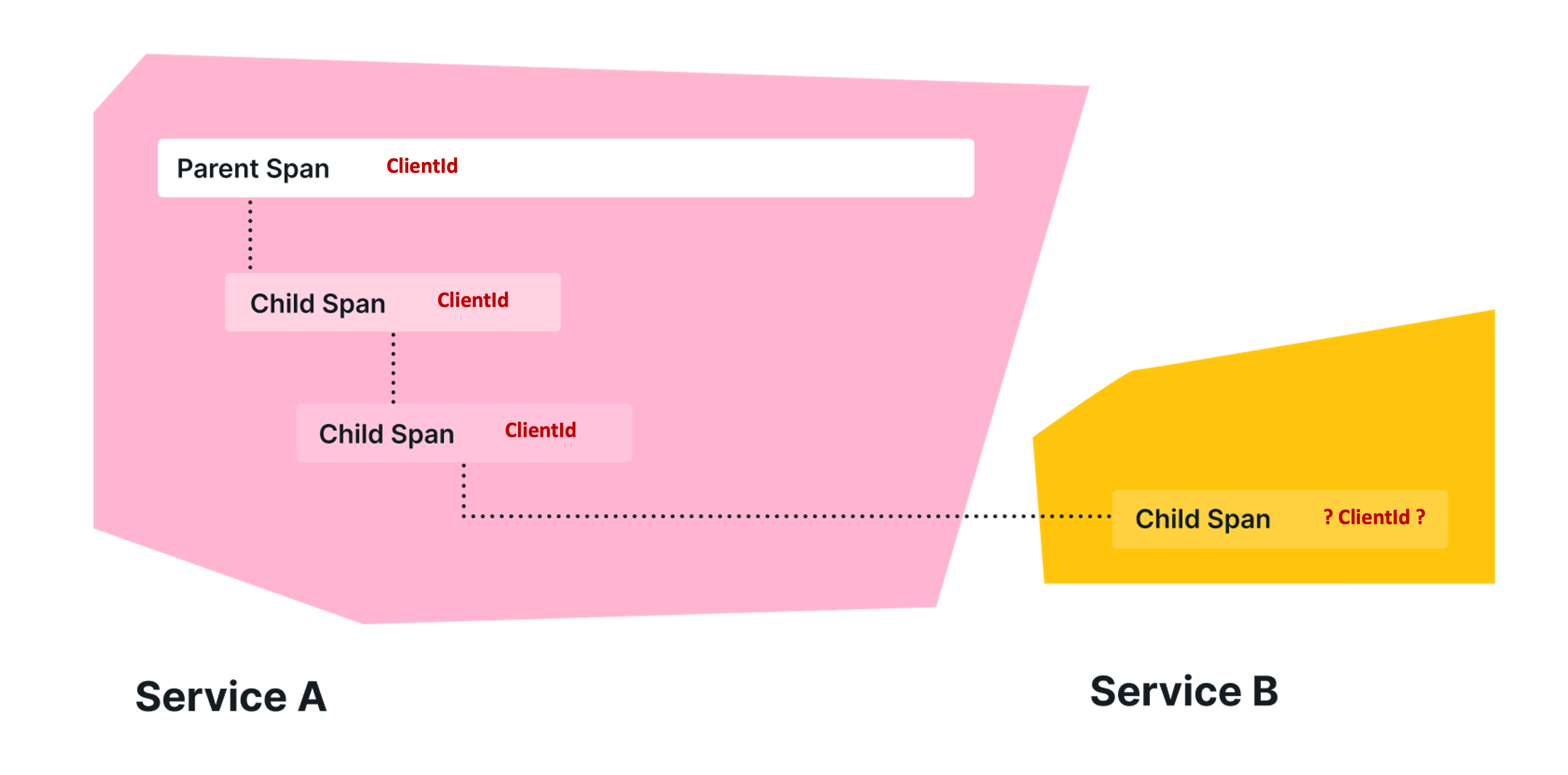
比如说,在kubegems中有两个服务:api 和agent,以一次用户请求获取k8s资源为例:
- api: 解析用户token,校验用户信息,再交给
agent获取对应集群的k8s资源 - agent: 不再处理用户信息,直接调用k8s api并返回
在这种情况下,假如我们想要在agent的trace信息中,知道这个请求时哪个用户发起的,就可以借助baggage来实现:
首先,初始化TextMapPropagator时,需要加上Baggage Propagator:
otel.SetTextMapPropagator(propagation.NewCompositeTextMapPropagator(propagation.TraceContext{}, propagation.Baggage{}))
然后,在api向agent发起请求时,注入user name的baggage:
import (
"net/http"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/propagation"
"go.opentelemetry.io/otel/baggage"
)
func DoRequest(){
...
userBaggage, err := baggage.Parse(fmt.Sprintf("user.id=%d,user.name=%s", user.ID, user.Username))
if err != nil {
otel.Handle(err)
}
req, err := http.NewRequestWithContext(baggage.ContextWithBaggage(ctx, userBaggage), clientreq.Method, addr, body)
if err != nil {
return nil, err
}
otel.GetTextMapPropagator().Inject(req.Context(), propagation.HeaderCarrier(req.Header))
http.DefaultClient.Do(req)
...
}
最后,在agent解析baggage并设置为attributes:
import (
"go.opentelemetry.io/otel/propagation"
"go.opentelemetry.io/otel/baggage"
)
func HandleRequest(){
...
// extract from http.Request by propagator to do distribute tracing
ctx := cfg.Propagators.Extract(req.Context(), propagation.HeaderCarrier(req.Header))
ctx, span := tracer.Start(ctx, spanName, opts...)
defer span.End()
reqBaggage := baggage.FromContext(ctx)
span.SetAttributes(
attribute.String("user.id", reqBaggage.Member("user.id").Value()),
attribute.String("user.name", reqBaggage.Member("user.name").Value()),
)
req = req.WithContext(ctx)
...
}
如果你想了解更多关于Baggage的信息,可以阅读文档:https://www.w3.org/TR/baggage/,因为它遵从`W3C Baggage format`标准。
理解propagator
无论是TraceContext还是Baggage,在我们选用的TextMapPropagator中,都是采用TextMapCarrier来实现
// TextMapCarrier is the storage medium used by a TextMapPropagator.
type TextMapCarrier interface {
...
}
而TextMapCarrier,目前的唯一实现是HeaderCarrier:
// HeaderCarrier adapts http.Header to satisfy the TextMapCarrier interface.
type HeaderCarrier http.Header
也就是说,不管我们采用http还是grpc协议,只要我们采用TextMapPropagator,实现信息传播的,是http协议 header。
我们可以通过Debug来追踪这一过程,首先, 在client端的Inject方法打上断点,观察它是怎么把要传播的信息注入进去的:
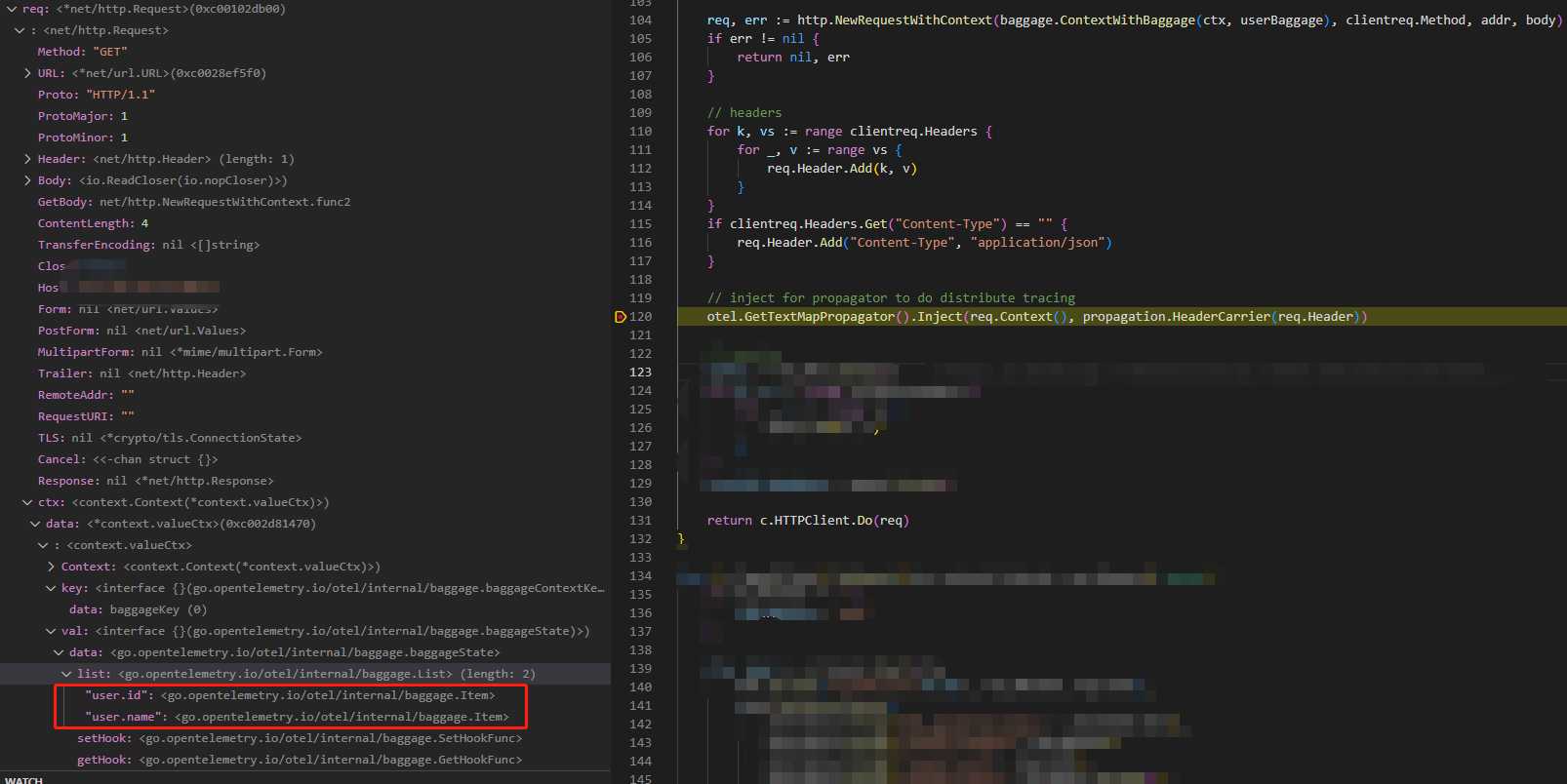
可以看到,注入前 context 已经带有了user.id和user.name信息,然后下一步:
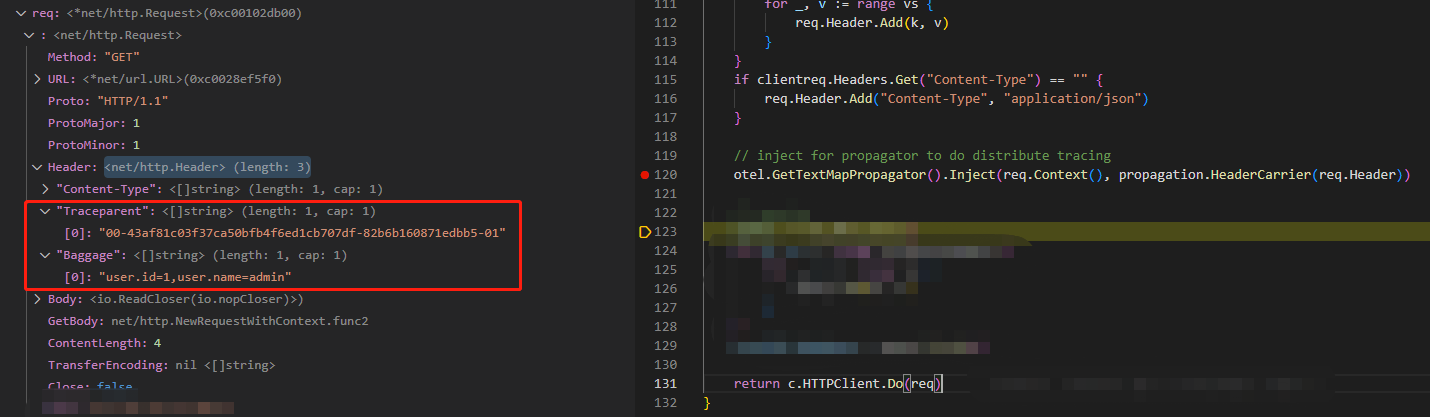
通过把ctx带的信息注入进headr, 此时请求的Header中已经带有了Traceparent和Baggage信息。
然后我们在server端的Extract方法打上断点,观察它是怎么解析出传播的信息的。
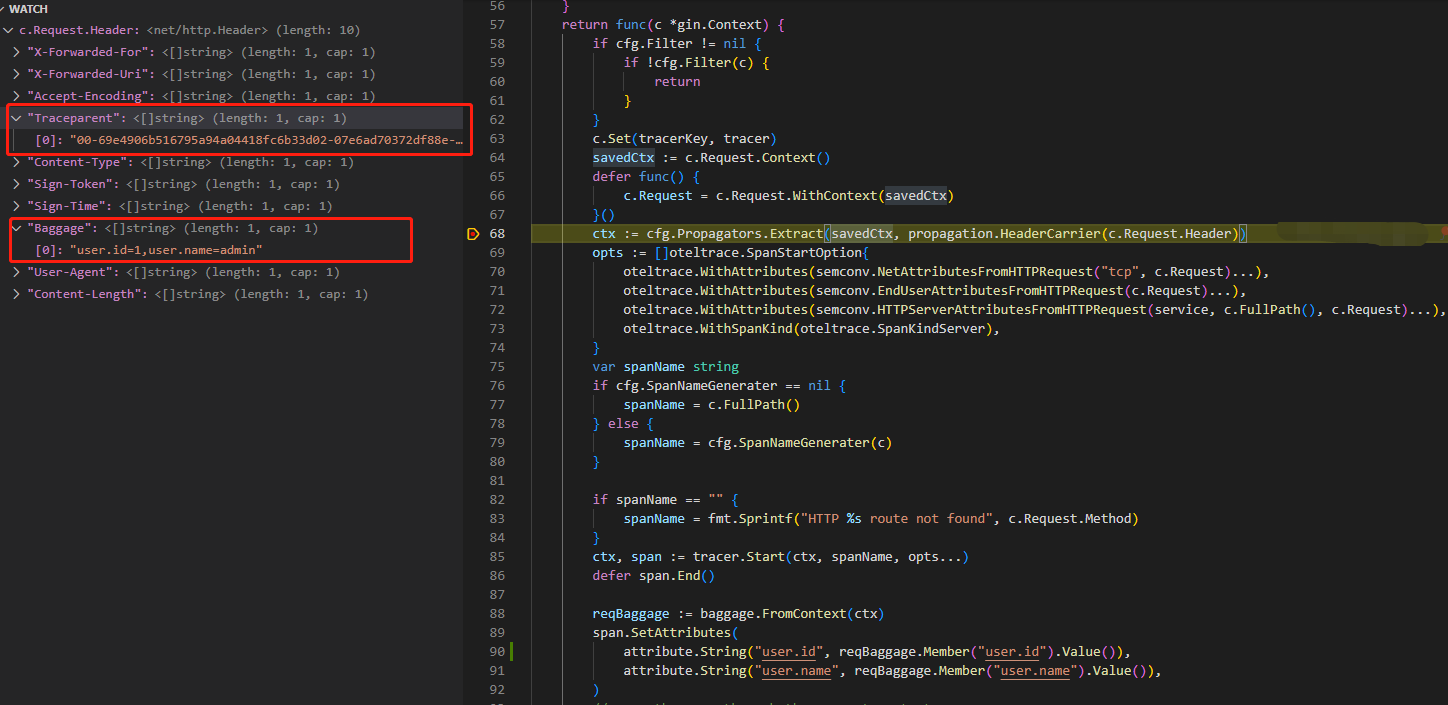

很显然,它通过从client请求的header中提取Traceparent来获取traceID和spanID,来关联上下游,再提取Baggage来获取来自client的信息。
其他形式的propagator
对基于http协议的进程间通信,我们使用TextMapPropagator完全足够,但如果说要针对没有HeaderCarrier实现的通信协议,官方有计划开发binary propagator来实现, 详见 https://github.com/open-telemetry/opentelemetry-specification/issues/437
Metrics(alpha)
由于opentelemety go标准库的metric实现还是alpha,极不稳定,文档几乎没有,请谨慎使用。
初始化
import (
"context"
"go.opentelemetry.io/otel/exporters/otlp/otlpmetric/otlpmetrichttp"
"go.opentelemetry.io/otel/metric/global"
sdkmetric "go.opentelemetry.io/otel/sdk/metric"
)
func initMeter(ctx context.Context) (*sdkmetric.MeterProvider, error) {
exp, err := otlpmetrichttp.New(ctx)
if err != nil {
return nil, err
}
mp := sdkmetric.NewMeterProvider(sdkmetric.WithReader(sdkmetric.NewPeriodicReader(exp, sdkmetric.WithInterval(15*time.Second))))
global.SetMeterProvider(mp)
return mp, nil
}
要注意的配置主要是NewPeriodicReader(), 它用来设置我们收集并向opentelemetry collector发送指标的时间间隔。
在kubegems上,我们的opentelemetry collector使用的是pometheus exporter来导出监控指标,并设置有30s的scrape_interval,因此,我们这里的WithInterval()最好是小于30s以保证监控数据的及时性。
使用
以下的示例是kubegems为gin框架添加的metrics实现,参照了net/http的opentelemetry实现(https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/net/http/otelhttp),记录了两个指标:
http.server.request_count: 请求总量http.server.duration:请求耗时(ms)
import (
"time"
"github.com/gin-gonic/gin"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/metric/global"
"go.opentelemetry.io/otel/metric/instrument/syncfloat64"
"go.opentelemetry.io/otel/metric/instrument/syncint64"
"go.opentelemetry.io/otel/propagation"
semconv "go.opentelemetry.io/otel/semconv/v1.12.0"
)
// Server HTTP metrics.
const (
RequestCount = "http.server.request_count" // Incoming request count total
ServerLatency = "http.server.duration" // Incoming end to end duration, microseconds
)
const (
instrumentationName = "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
)
var (
counters map[string]syncint64.Counter
valueRecorders map[string]syncfloat64.Histogram
)
func MeterMiddleware(service string) gin.HandlerFunc {
counters = make(map[string]syncint64.Counter)
valueRecorders = make(map[string]syncfloat64.Histogram)
meter := global.MeterProvider().Meter(instrumentationName)
requestCounter, _ := meter.SyncInt64().Counter(RequestCount)
serverLatencyMeasure, _ := meter.SyncFloat64().Histogram(ServerLatency)
counters[RequestCount] = requestCounter
valueRecorders[ServerLatency] = serverLatencyMeasure
return func(c *gin.Context) {
requestStartTime := time.Now()
attributes := semconv.HTTPServerMetricAttributesFromHTTPRequest(service, c.Request)
ctx := otel.GetTextMapPropagator().Extract(c.Request.Context(), propagation.HeaderCarrier(c.Request.Header))
c.Next()
// Use floating point division here for higher precision (instead of Millisecond method).
// 由于Bucket分辨率的问题,这里只能记录为millseconds而不是seconds
elapsedTime := float64(time.Since(requestStartTime)) / float64(time.Millisecond)
counters[RequestCount].Add(ctx, 1, attributes...)
valueRecorders[ServerLatency].Record(ctx, elapsedTime, attributes...)
}
}
Log (not implemented yet)
opentelemetry 目前还未针对go有相关的实现。
但是,假如我们的应用运行在kubegems上,其中的日志收集、查询功能本身就提供了相关的能力,所以在官方的标准推出之前,我们也可以先通过span.SpanContext().TraceID()获取trace-id,自行在日志中打印trace-id,来实现trace-log关联。
下面以gin 和beego框架为例,简单讲解一下:
gin可以添加个打印日志的middleware:
func logMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
ctx := otel.GetTextMapPropagator().Extract(c.Request.Context(), propagation.HeaderCarrier(c.Request.Header))
span := trace.SpanFromContext(ctx)
c.Next()
statusCode := c.Writer.Status()
logrus.WithFields(logrus.Fields{
"method": c.Request.Method,
"path": c.Request.URL.Path,
"trace-id": span.SpanContext().TraceID(),
"code": statusCode,
"latency": time.Since(start).String(),
"sampled": span.SpanContext().IsSampled(),
}).Info(http.StatusText(statusCode))
}
}
beego可以添加个filter:
beego.InsertFilter("*", beego.BeforeRouter, func(c *bcontext.Context) {
ctx := otel.GetTextMapPropagator().Extract(c.Request.Context(), propagation.HeaderCarrier(c.Request.Header))
newctx, span := tracer.Start(ctx, "getUserFromBaggage")
defer span.End()
logrus.WithFields(logrus.Fields{
"method": c.Request.Method,
"path": c.Request.URL.Path,
"trace-id": span.SpanContext().TraceID(),
"sampled": span.SpanContext().IsSampled(),
}).Info("handle request")
reqBaggage := baggage.FromContext(newctx)
span.SetAttributes(
attribute.String("user.id", reqBaggage.Member("user.id").Value()),
attribute.String("user.name", reqBaggage.Member("user.name").Value()),
)
c.Request = c.Request.WithContext(newctx)
})
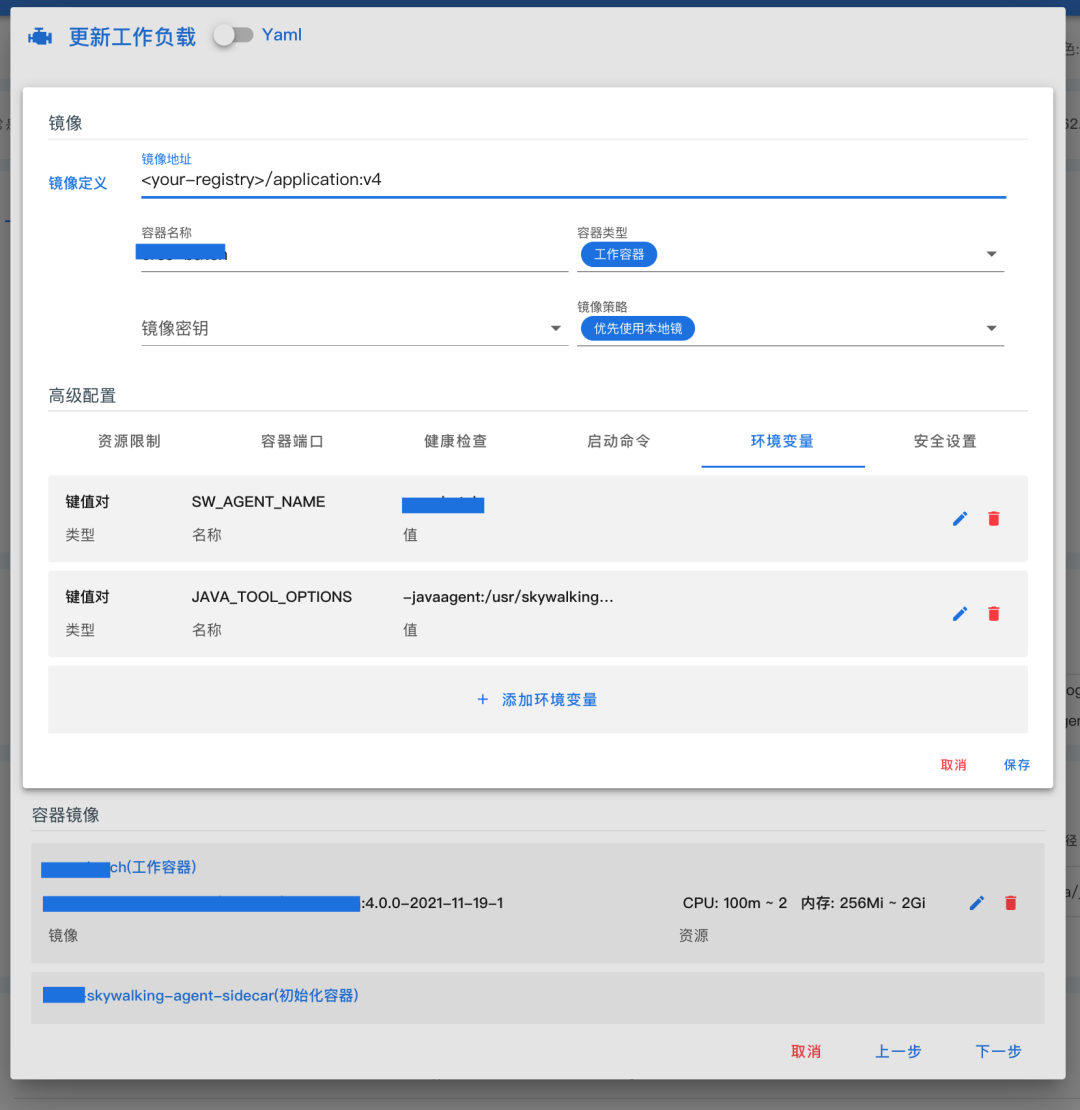
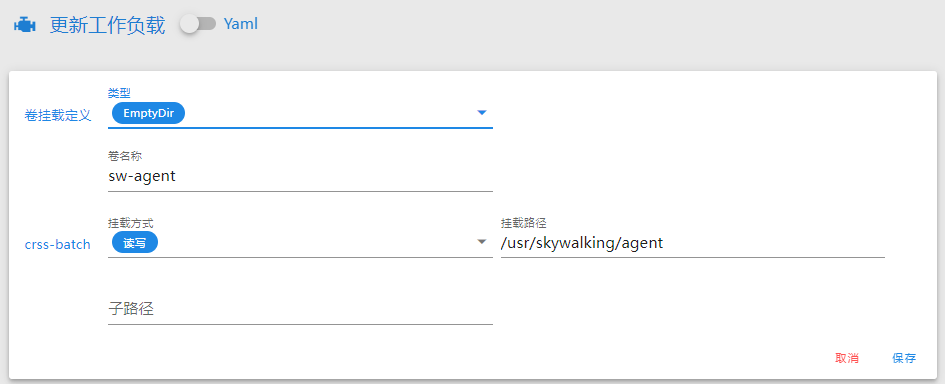
Kubegems接入Opentelemetry
假如我们的应用程序,已经在代码层面接入了opentelemetry,我们只需要为其添加几个环境变量(为统一kubegems上应用程序的接入,不建议修改):
- name: OTEL_K8S_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: OTEL_K8S_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: OTEL_SERVICE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.labels['app']
- name: OTEL_K8S_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: OTEL_RESOURCE_ATTRIBUTES
value: service.name=$(OTEL_SERVICE_NAME),namespace=$(OTEL_K8S_NAMESPACE),node=$(OTEL_K8S_NODE_NAME),pod=$(OTEL_K8S_POD_NAME)
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://opentelemetry-collector.observability:4318 # grpc change to 4317 port
- name: OTEL_EXPORTER_OTLP_INSECURE
value: "true"
示例程序
我们通过示例程序 otel-demo来演示、使用opentelemetry基本功能,该demo功能如下:
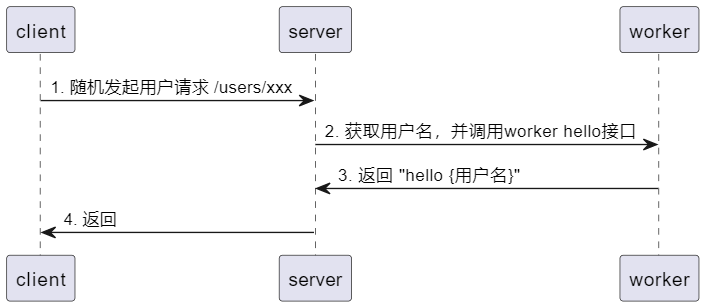
代码演示
获取代码并部署:
$ git clone https://github.com/jojotong/otel-demo.git
$ cd otel-demo
$ make build docker-build docker-push deploy
重点:sampler, propagator, baggage使用,gorm接入
kubegems功能演示
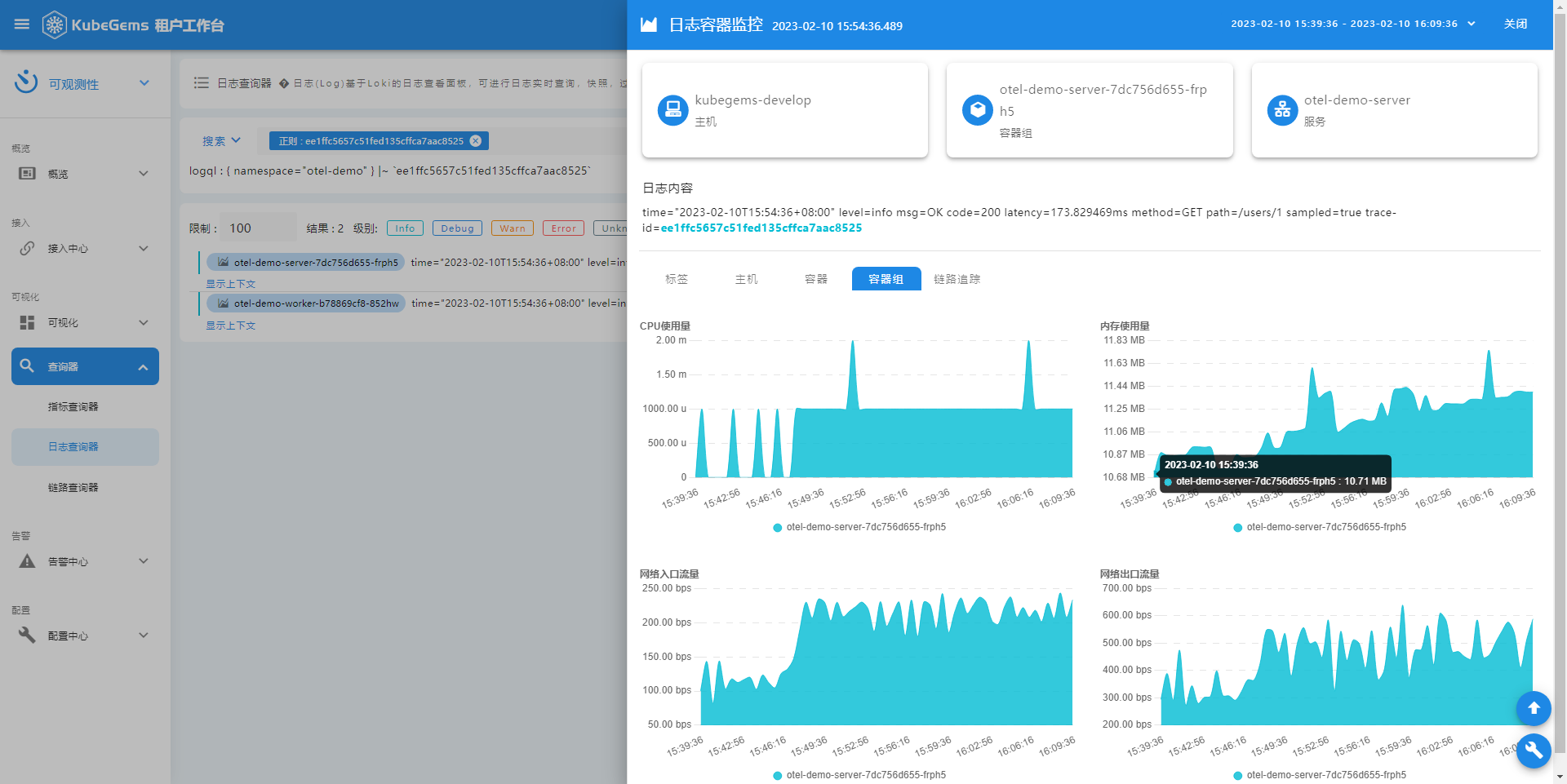
重点:trace, metric, log 联动查询
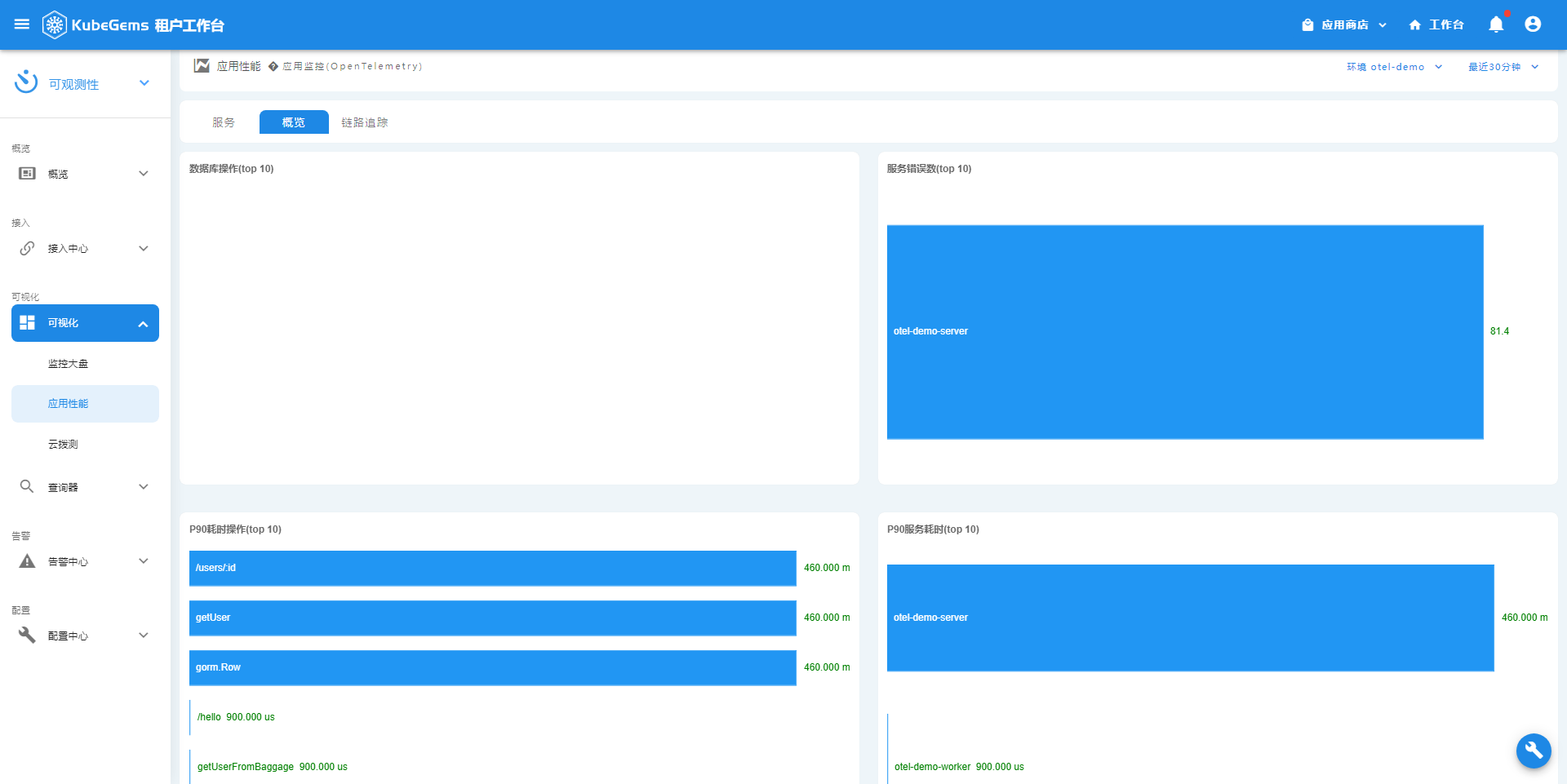
应用性能
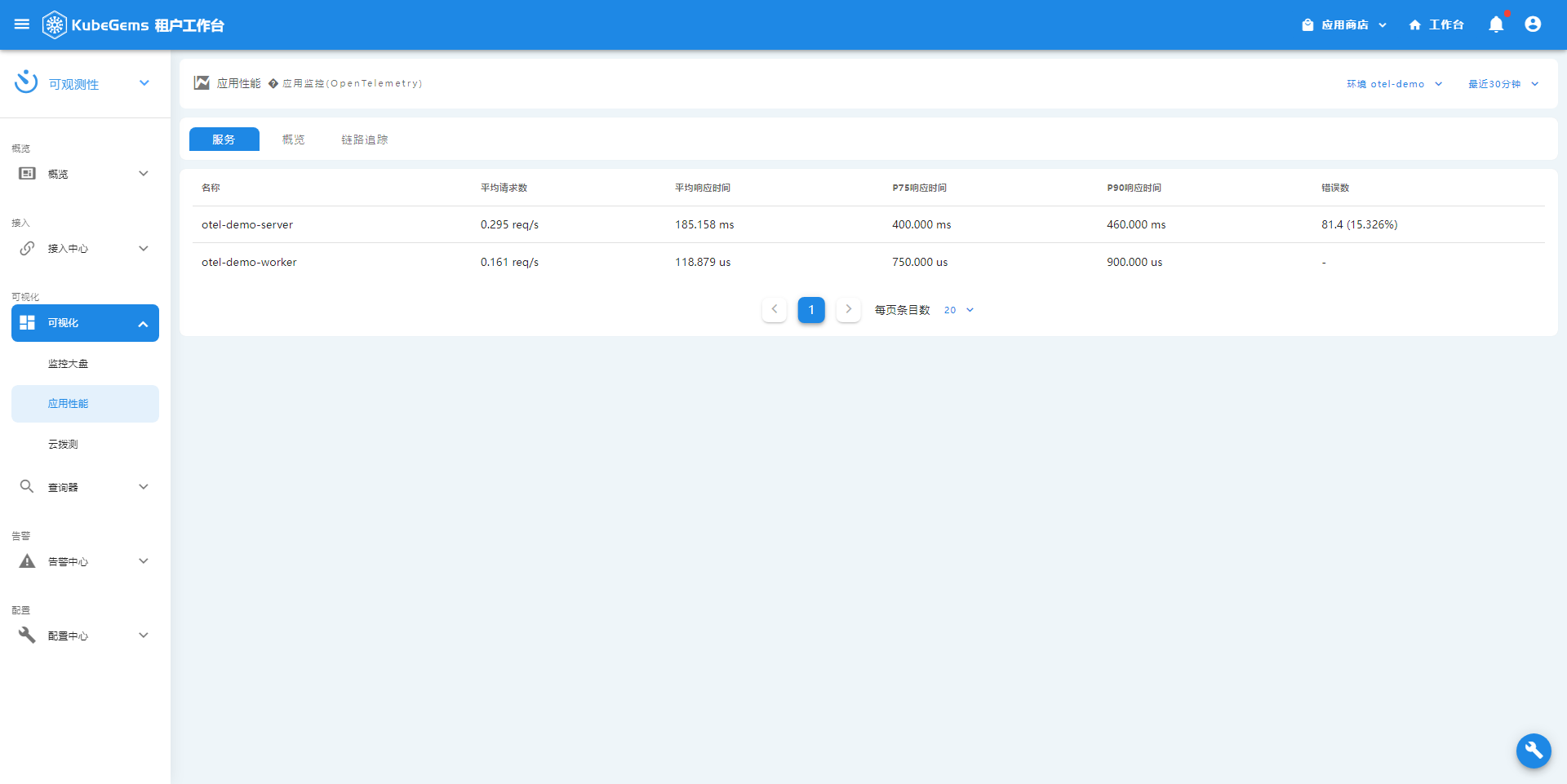

trace详情
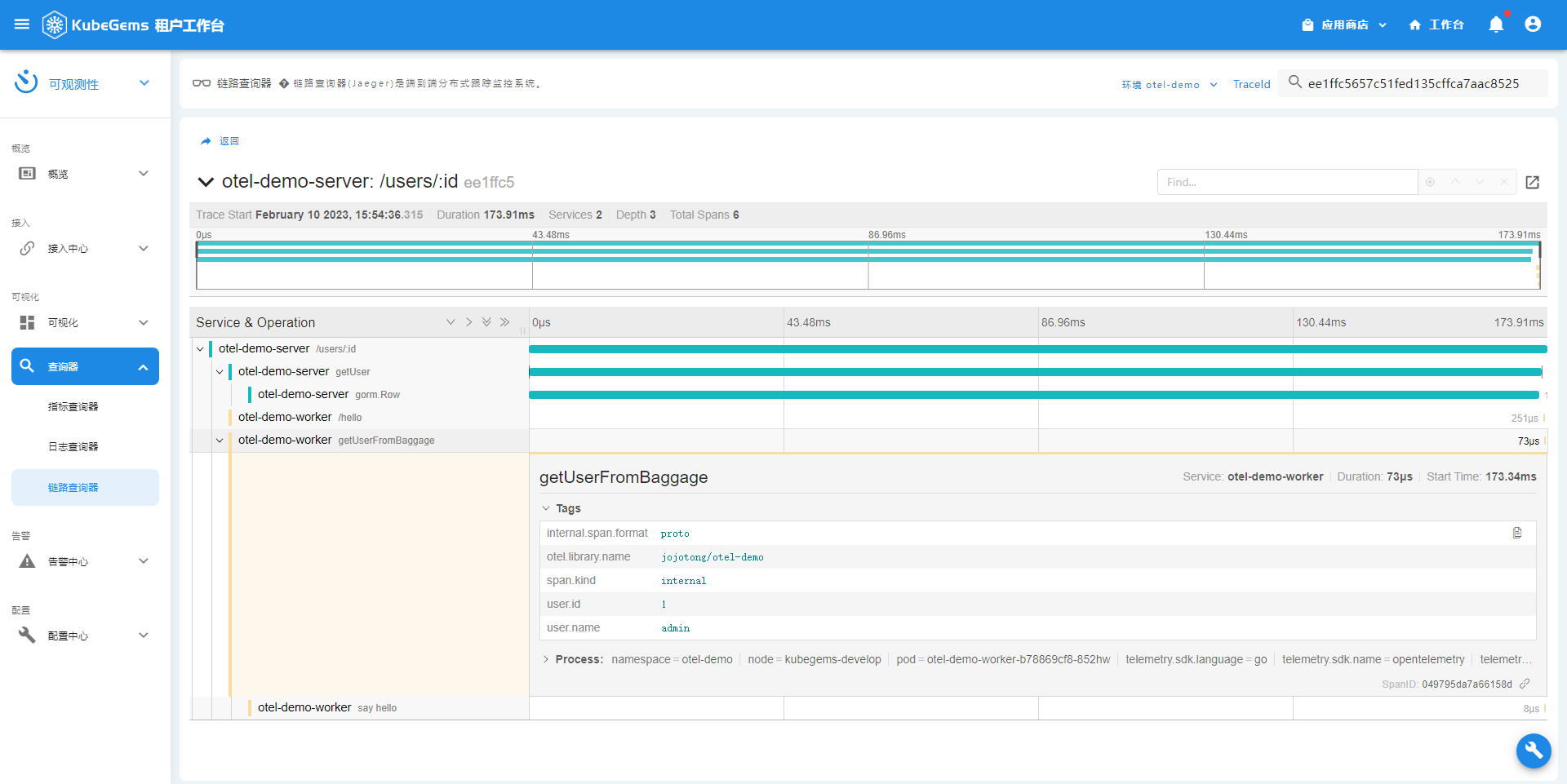
trace -> log
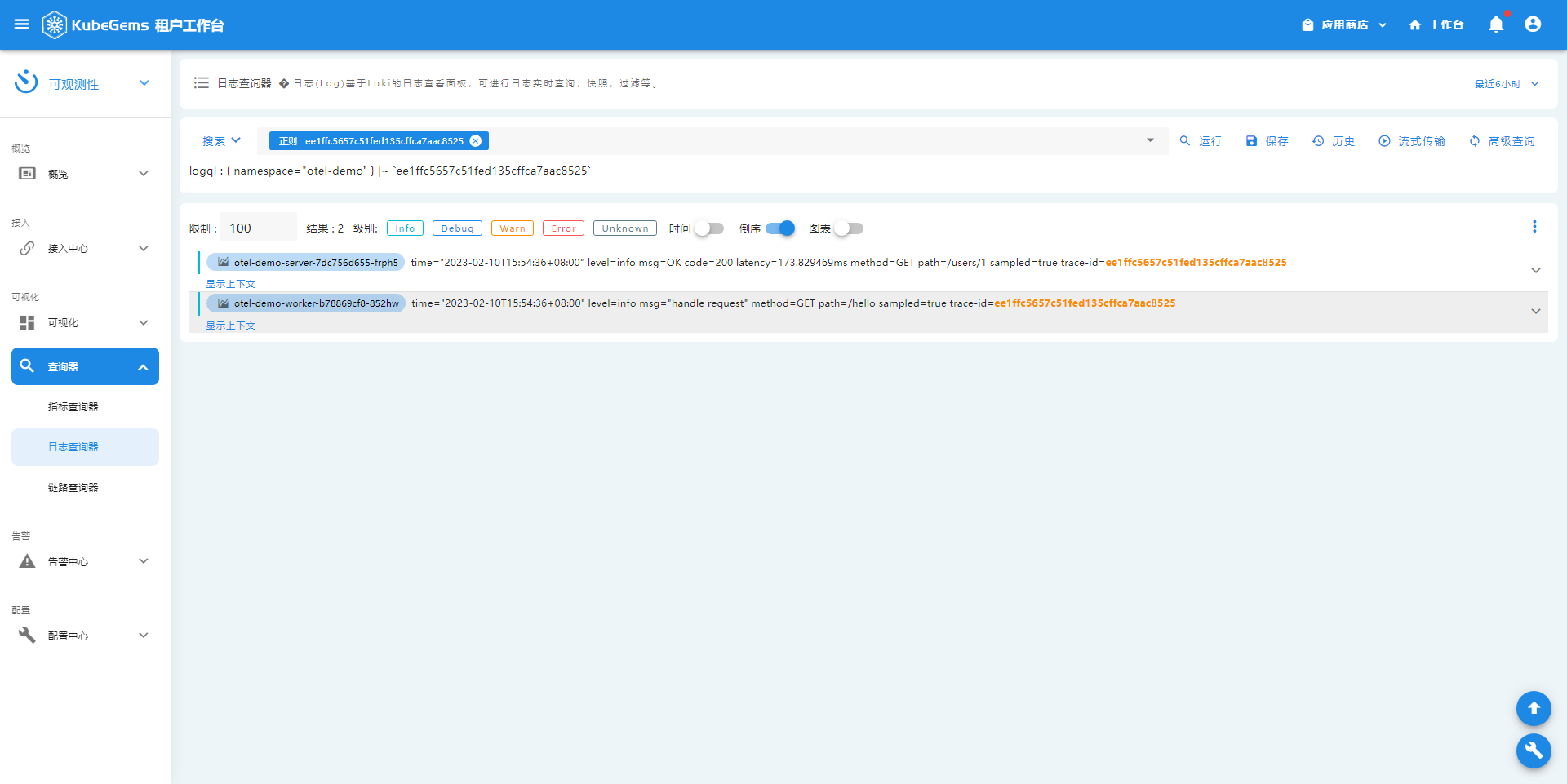
log -> monitor