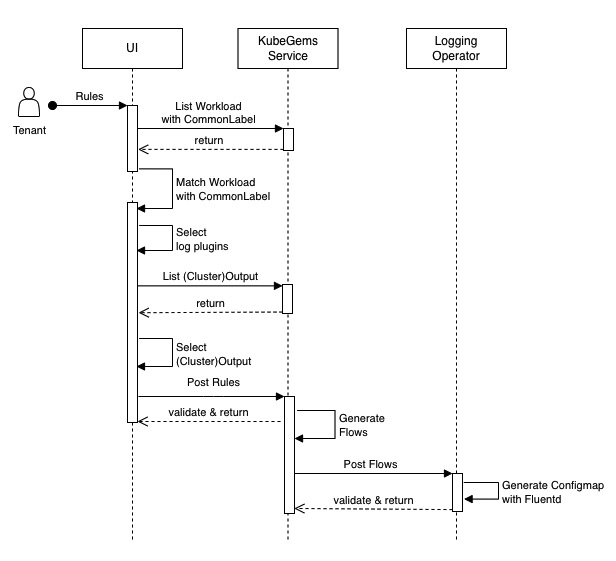
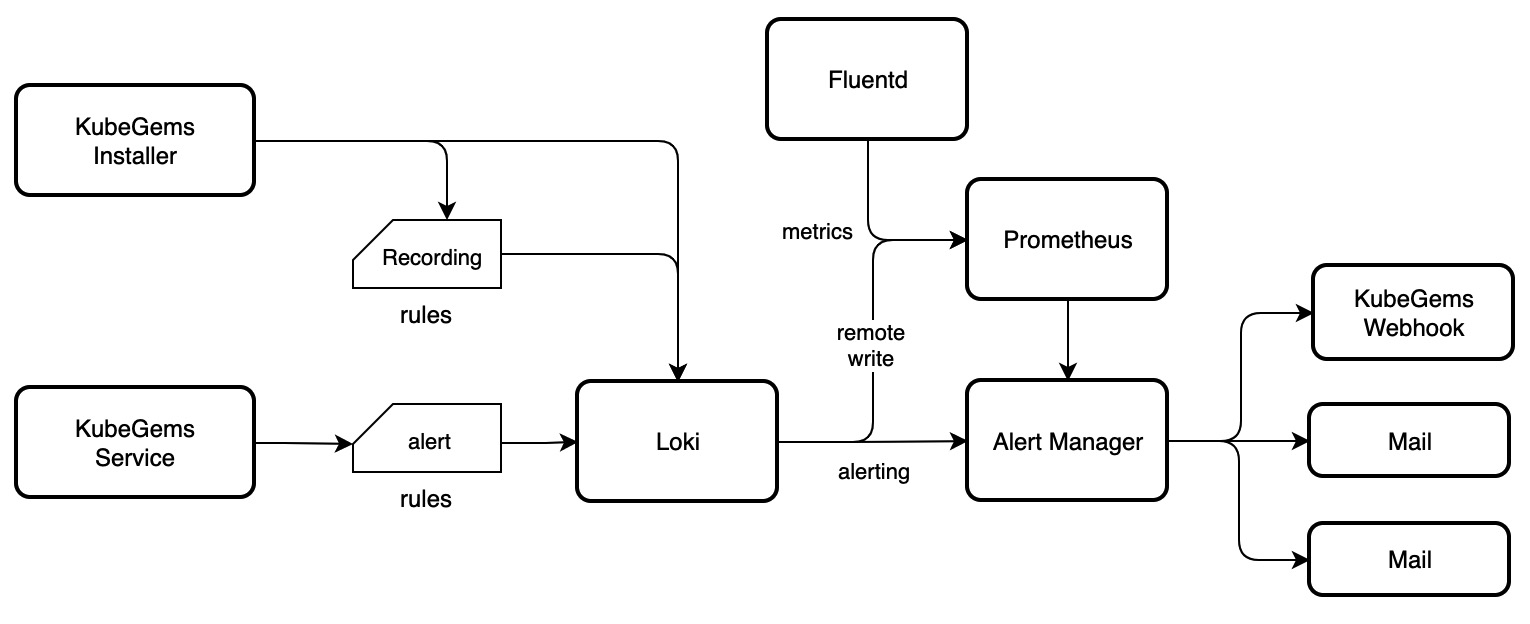
KubeGems 是一款开源的企业级多租户容器云平台。围绕云原生社区,KubeGems 提供了多 Kubernetes 集群接入能力,并具备丰富的组件管理和资源成本分析功能,能够帮助企业快速的构建和打造一个本地化、功能强大且低成本的云管理平台。
KubeGems 发行版本的主要愿景如下:
产品化开箱即用。确保 KubeGems 安装部署可以快速上手,并支持在界面中自我更新充分依托 CNCF 生态。 插件中心全面转向在线仓库,确保 KubeGems 始终使用云原生生态体系,形成围绕以 Kubernetes 为核心的云原生操作系统引入OpenTelemetry 可观测性。确保平台应用的各项 Metrics、Trace、Log 数据能够相互联通,提高用户查询效率机器学习 MLOps 自动化。支持海量在线(HuggingFace 、 OpenMMlab)、离线(ModelX)AI 算法的自动化部署与预览,推动云原生 AI 发展边缘计算与设备管理。KubeGems Edge 与 Rancher k3s 联合完成对边缘 K3S 集群的云端统一管理,确保云边协同任务开展。
KubeGems 是 2022 年 3 月底在 GitHub(https://github.com/kubegems) 开源一款云端 PaaS 产品。历经1年,3个主版本的迭代,我们正式推出 v1.23 发行版的 GA 版本,欢迎试用并在 KubeGems 社区进行反馈。目前我们提供了在线 Demo 环境(https://demo.kubegems.io) ,后续我们也会长期跟踪 Kubernetes 和 CNCF社区的上游版本演进。
快速上手
安装部署
基于 Kubernetes 1.23.14 版本部署
- 确定部署版本
export KUBEGEMS_VERSION=<kubegems version>
- 部署 kubegems installer
kubectl create namespace kubegems-installer
kubectl apply -f https://github.com/kubegems/kubegems/raw/${KUBEGEMS_VERSION}/deploy/installer.yaml
- (可选)安装本地盘存储
kubectl create namespace local-path-storage
kubectl apply -f https://github.com/kubegems/kubegems/raw/${KUBEGEMS_VERSION}/deploy/addon-local-path-provisioner.yaml
- 部署 kubegems 核心组件
kubectl create namespace kubegems
export STORAGE_CLASS=local-path # 改为您使用的 storageClass
curl -sL https://github.com/kubegems/kubegems/raw/${KUBEGEMS_VERSION}/deploy/kubegems.yaml \
| sed -e "s/local-path/${STORAGE_CLASS}/g" \
> kubegems.yaml
kubectl apply -f kubegems.yaml
kubegems 所有服务部署并启动完成后会有如下 pod:
$ kubectl -n kubegems get pod
NAME READY STATUS RESTARTS AGE
kubegems-api-6d45f656f8-lfk7j 1/1 Running 0 21h
kubegems-argo-cd-app-controller-5b849bfb49-ltvdz 1/1 Running 0 21h
kubegems-argo-cd-repo-server-7dddd8f57d-ldj5k 1/1 Running 0 21h
kubegems-argo-cd-server-76745cc657-v8dx9 1/1 Running 0 21h
kubegems-chartmuseum-6c546b4d-qxfjj 1/1 Running 0 21h
kubegems-charts-init-main-lmtwt 0/1 Completed 0 21h
kubegems-dashboard-6bcd7f65f-89gsk 1/1 Running 0 21h
kubegems-gitea-0 1/1 Running 0 21h
kubegems-init-main-vjxnq 0/1 Completed 3 21h
kubegems-msgbus-7c58548497-pqwht 1/1 Running 5 (21h ago) 21h
kubegems-mysql-0 1/1 Running 0 21h
kubegems-redis-master-0 1/1 Running 0 21h
kubegems-worker-7d67974f4c-cj65l 1/1 Running 5 (21h ago) 21h
访问仪表盘
编辑 kubegems 插件,为 dashbnoard 组件开启 nodeport
kubectl -n kubegems edit plugins.plugins.kubegems.io kubegems
示例:
apiVersion: plugins.kubegems.io/v1beta1
kind: Plugin
metadata:
annotations:
plugins.kubegems.io/category: core/KubeGems
plugins.kubegems.io/description: KubeGems core service and dashboard.
plugins.kubegems.io/required: "true"
name: kubegems
namespace: kubegems-installer
spec:
chart: kubegems
installNamespace: kubegems
kind: helm
url: https://charts.kubegems.io/kubegems
values:
dashboard:
service:
type: NodePort
您可以通过如下用户名与密码登录控制台:
user: admin password: demo!@#admin
1.23 功能特性
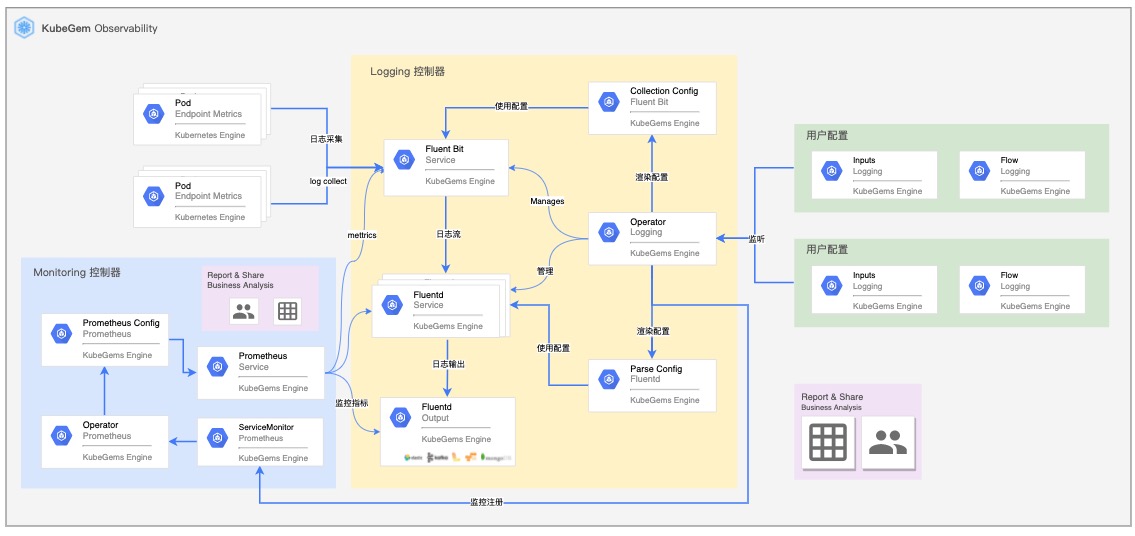
应用可观测性
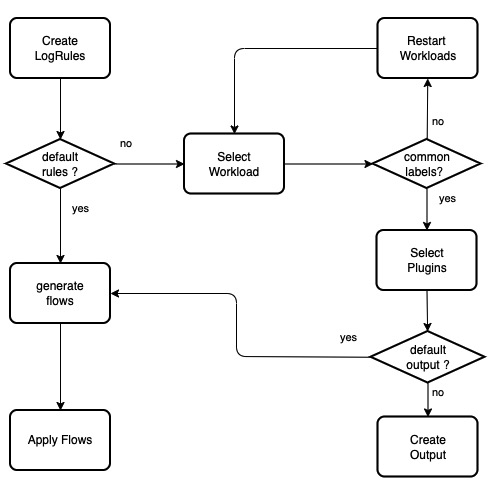
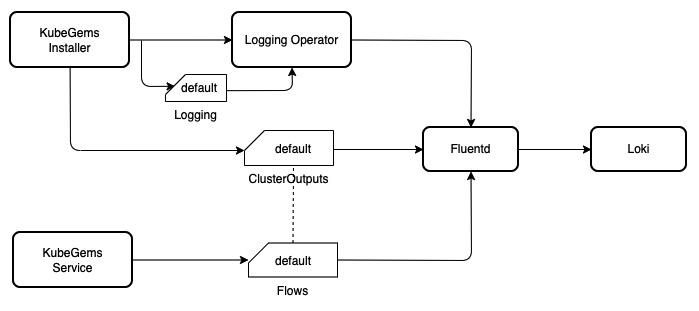
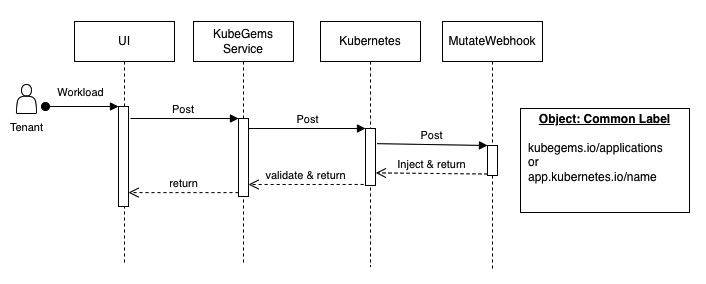
KubeGems 从 v1.23 开始引入 OpenTelemetry 作为其平台内部采集、分析应用信息的核心组件。并在平台内完成在多集群、多租户和多环境的场景下独立管理用户的监控大屏、日志采集和应用性能等数据。并通过云端统一的元数据进行跨数据维度的查询。
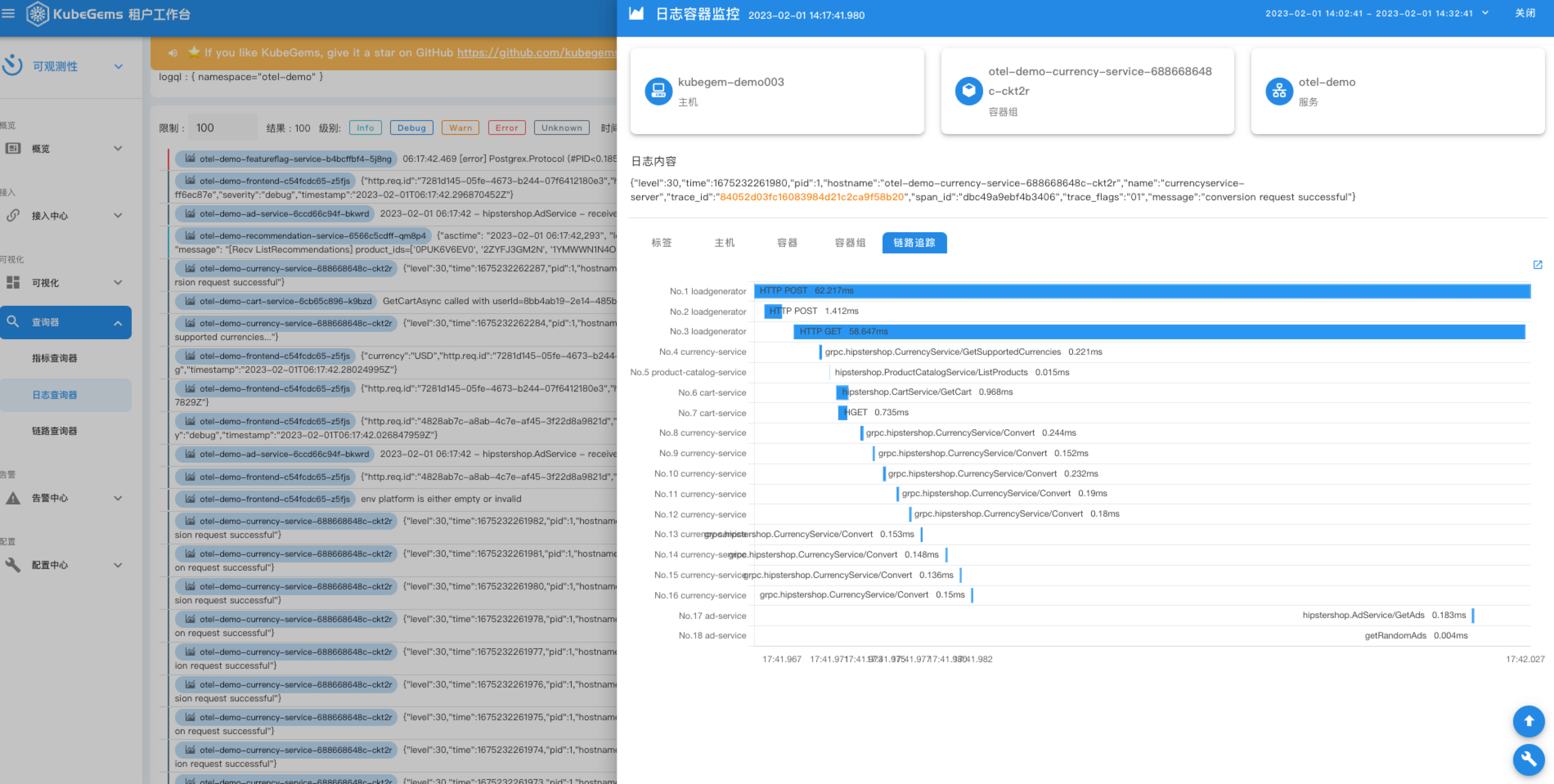
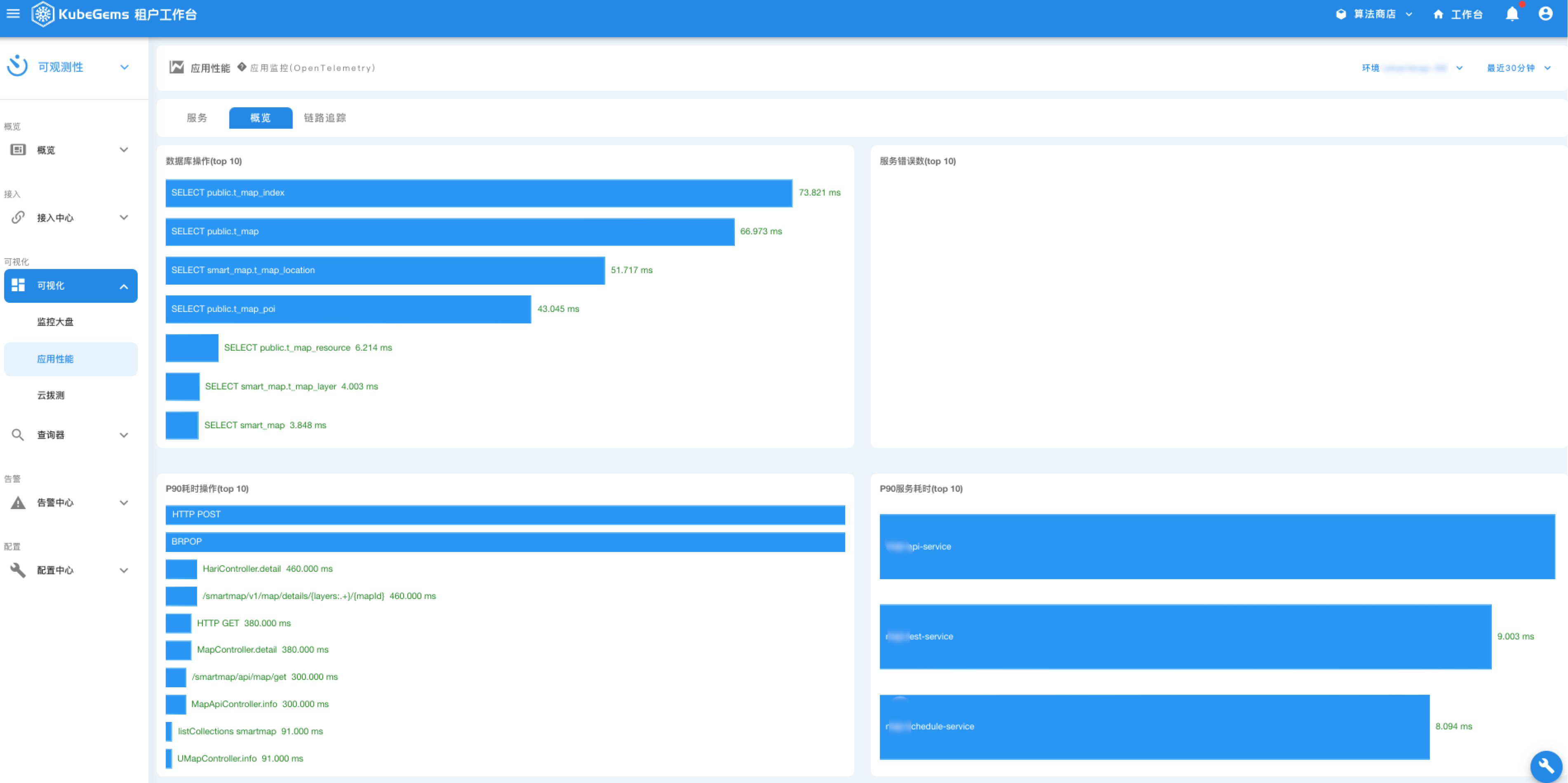
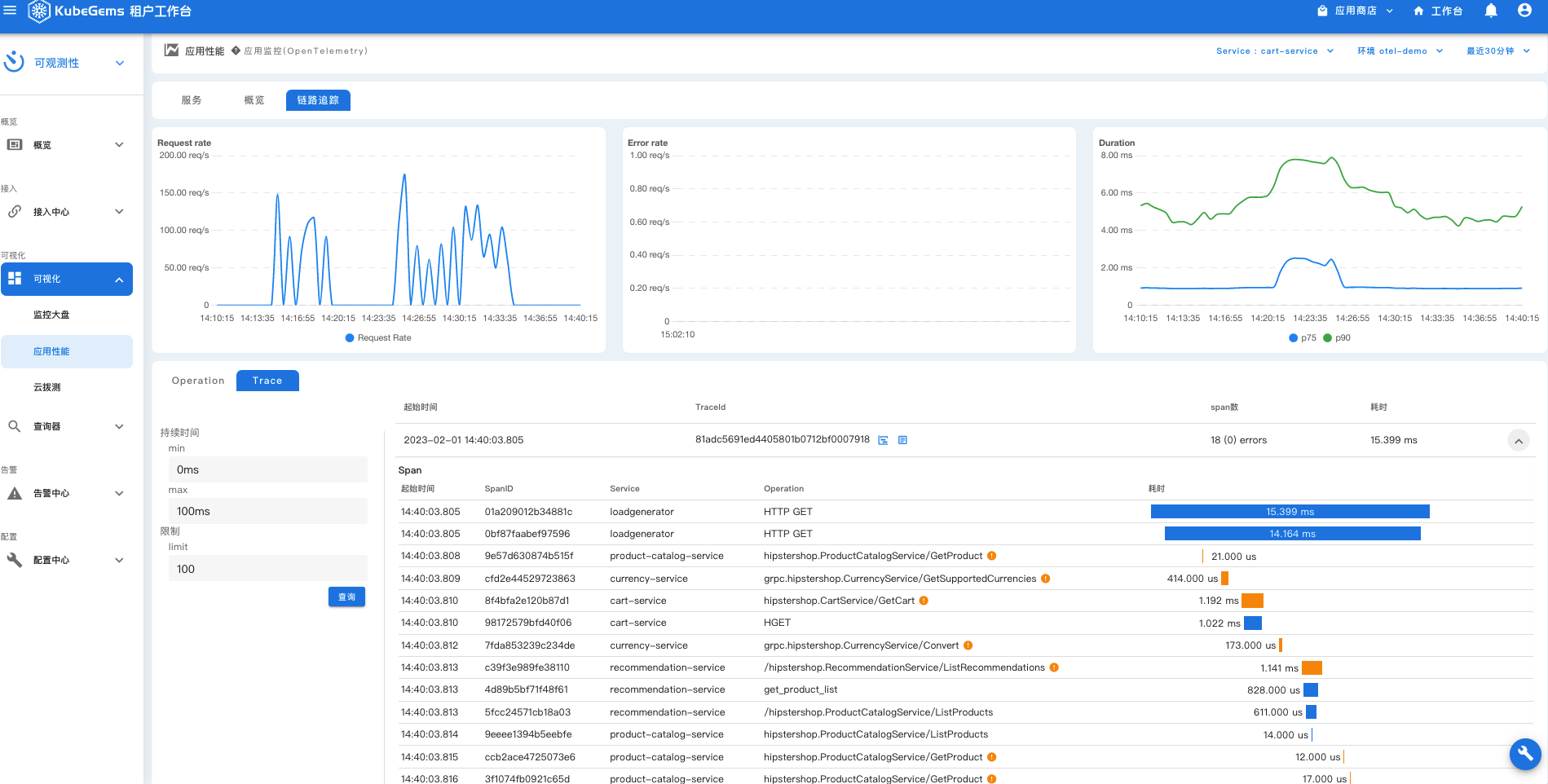
应用性能
应用在使用OpenTelemety SDK上报 Tracing 数据同时也由平台内置组件进行分析后形成应用统性能统计,便于用户实时掌控平台内应用运行状态
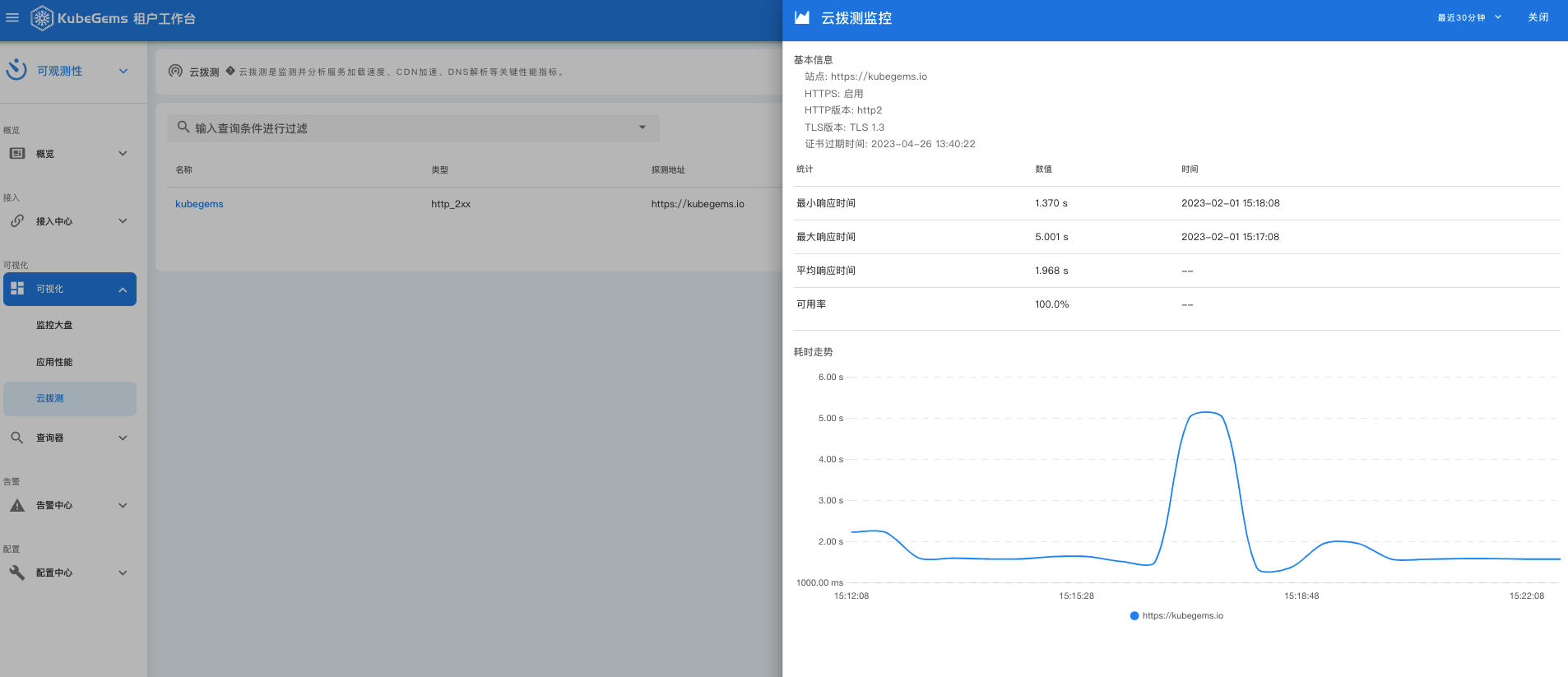
云拨测
云拨测为 KubeGems 用户提供开箱即用的主动拨测式应用监测解决方案,利用集群内(即将支持集群外)的 blackbox-exporter,对目标应用进行性能管理(HTTP)和网络性能监控(ICMP、TCP),先于终端用户挖掘故障隐患,助力KubeGems用户提升自身应用产品的用户体验。
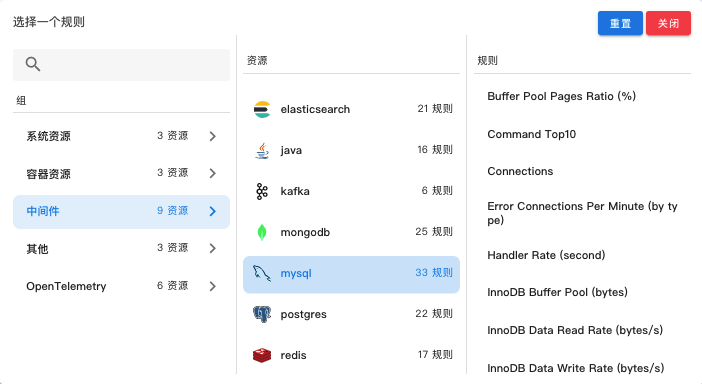
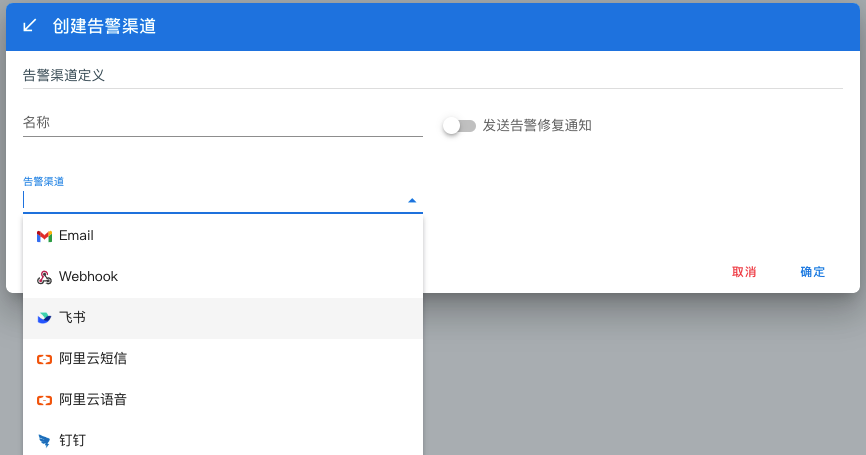
海量指标和告警渠道
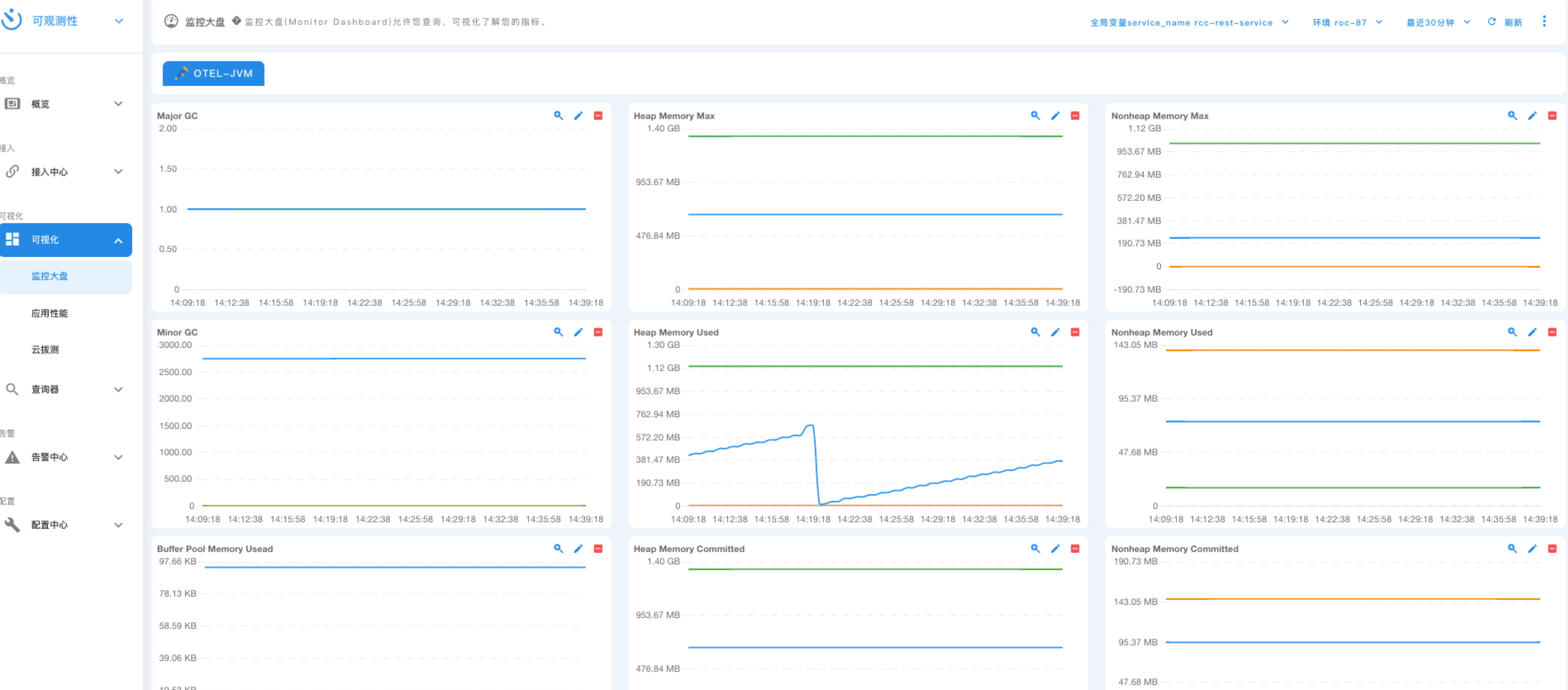
监控指标依托 Prometheus 实现对平台内容器、中间件、Otel 等服务指标的快速查询与过滤,通过内置模版节省用户大量时间。
通过创建告警通道,平台内用户可以制定针对特定监控对象的报警规则。当规则被触发时,系统会以您指定的报警方式向告警渠道中指定的接受者,以提醒您采取必要的问题解决措施。
Model Zoo
随着近年来人工智能产业的兴起,越来越多的 AI 算法服务部署在 Kubernetes 之上。KubeGems 自 1.22版本引入了 ModelX(https://github.com/kubegems/modelx)后,同时支持了在线和离线 Model Zoo 的接入
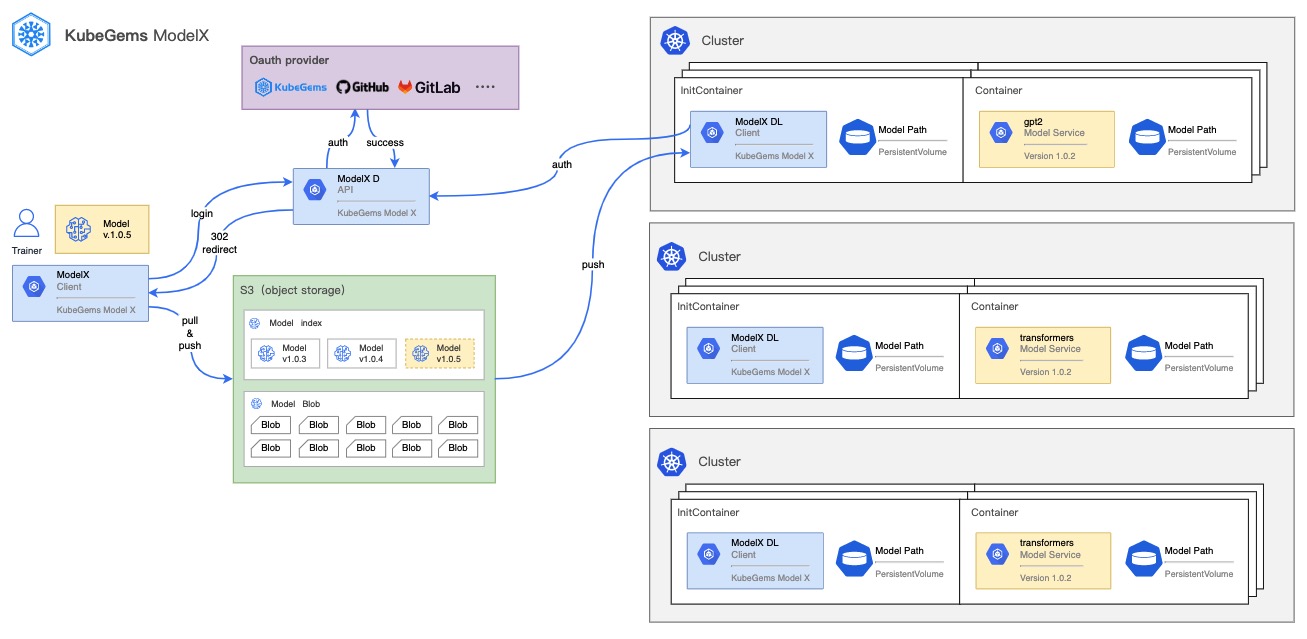
ModelX 一个轻量、高性能、可扩展的 AI 模型 ML/DL服务
KubeGems 1.23 版本迎来重大的功能更新,支持算法的实时预览。
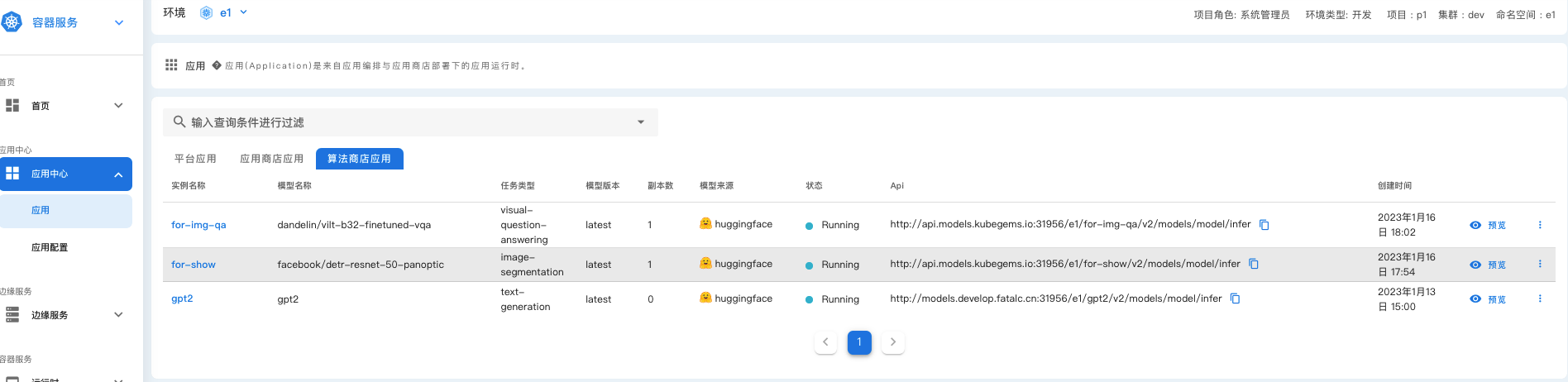
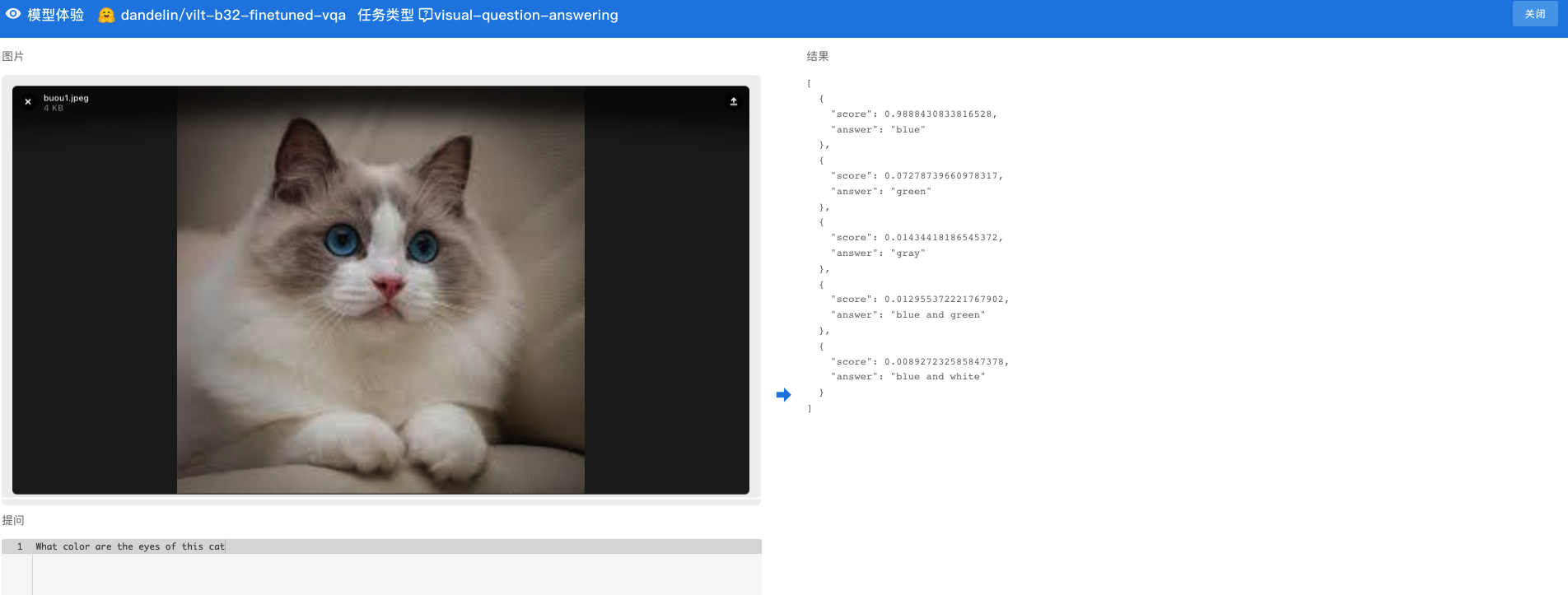
边缘计算
KubeGems 自 v1.23 版本开始,产品联合了 Rancher k3s 开启对边缘集群的管理。通过 Grpc Tunnel 技术实现了边缘 k3s 集群自主连接和上报心跳到云端。
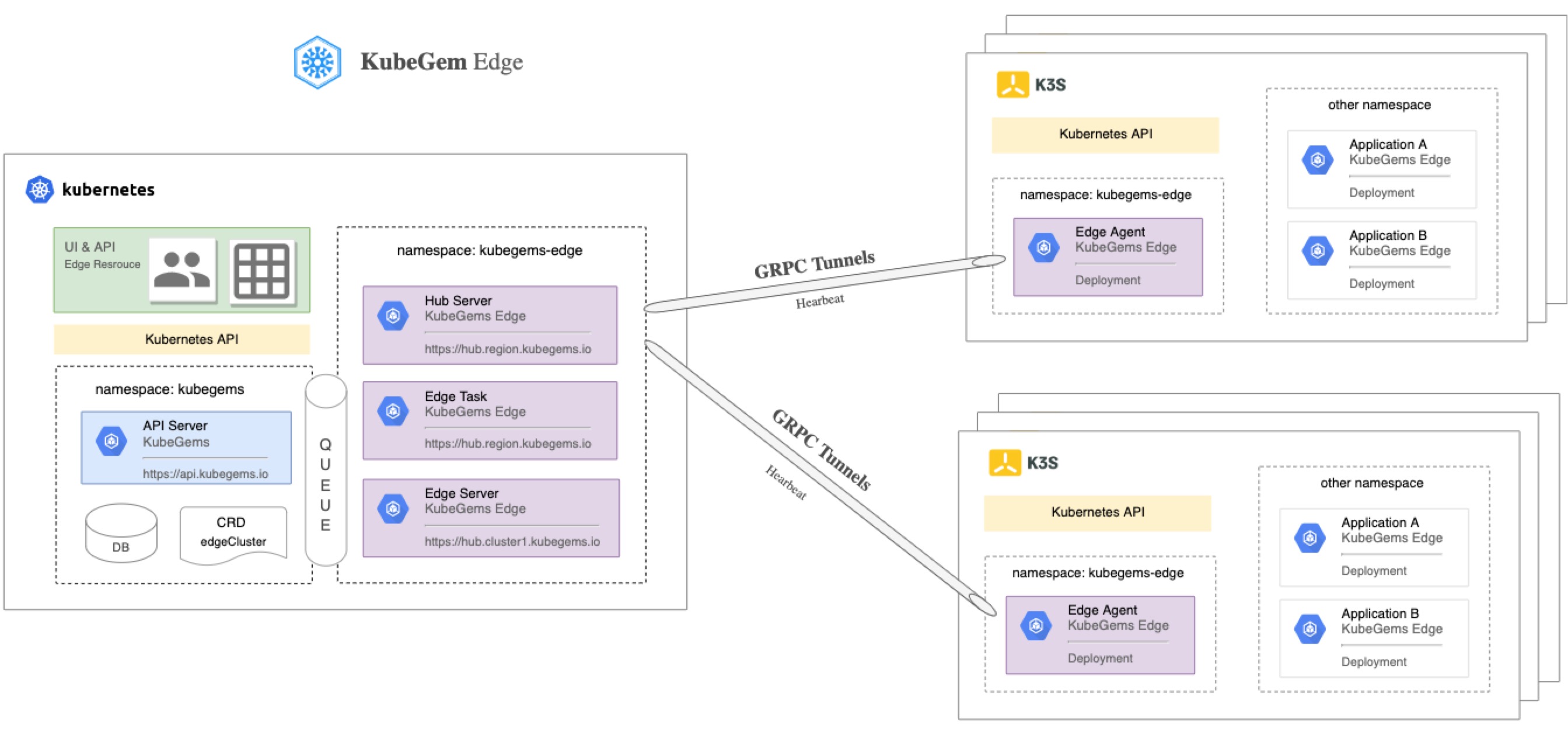
Edge Agent 由 Golang 开发,支持在 x86 和 arm 架构下运行。主要代理K3S API 服务以及与云端 Hub 服务建立 GRPC 隧道,并定时上报隧道和设备心跳数据
Edge Hub 管理边缘设备上连云端的隧道管理,并提供设备认证支持(计划中)
Edge Server KubeGems Edge 资源管理(CRD) 与 Edge API 服务
Edge Task (计划中) KubeGems Task 边缘设备任务调度服务,包含应用发布,(发送设备指令)等功能
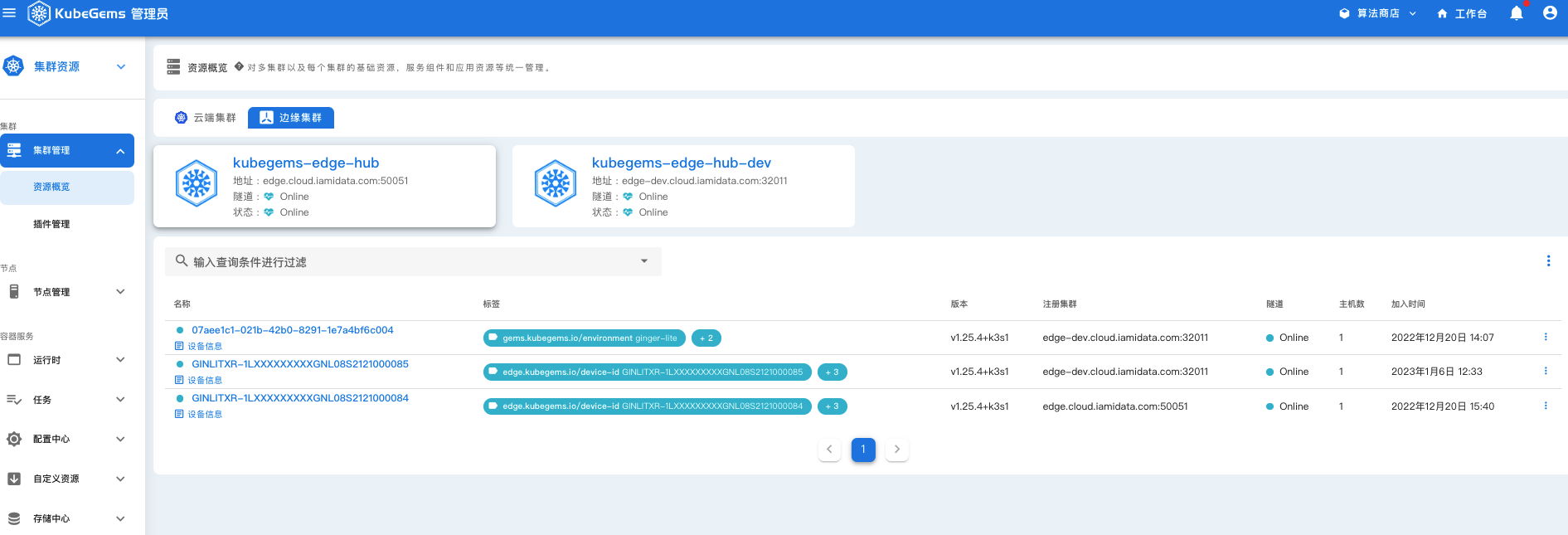
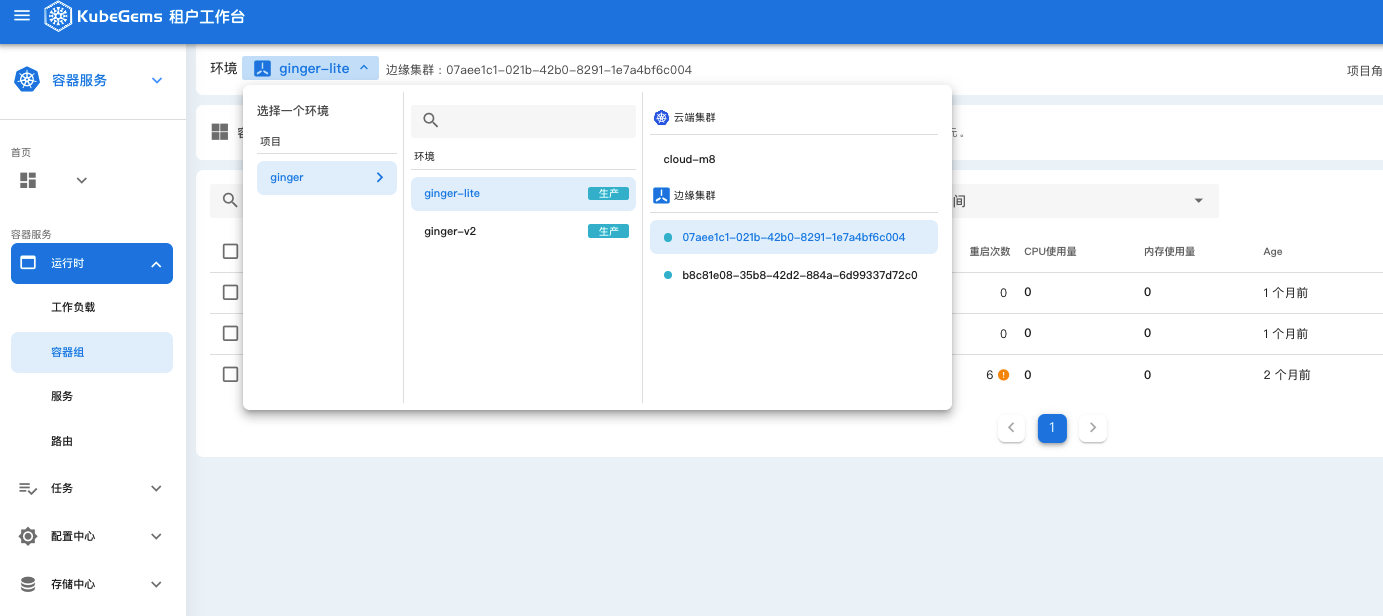
后续发展
KubeGems 当前仍然在高速的持续迭代,后续我们的规划也主要围绕 可观测性 、云原生生态和AIOps途径发展。您可以访问我们托管在 GitHub 上的 Project (https://github.com/orgs/kubegems/projects/9)来了解KubeGems最新动态,同时也欢迎任何人为项目提供有价值的议题!