
随着众多model zoo的出现,对于我们这样不懂得高深的数学基础知识的小白来说,能体验众多业界大牛开发的模型也不再是一个遥不可及的事情了。现在唯一的成本可能就是要熟悉各种开发框架,如 Transformers,OpenMMLab 等。KubeGems 在1.23版本中加入了模型商店的功能,其主要目的就是为了让开发者快速部署和体验这些优秀的模型,当前KubeGems主要对接Huggingface 和 OpenMMLab 两个model zoo,后续我们还将不断集成其他优秀的model zoo。本文将以HuggingFace为例,简单介绍如何在KubeGems上快速体验一个视觉问答的模型任务,以及一些实现背后的技术细节。
KubeGems模型商店
KubeGems 模型商店目前的设计目的是基于它来托管和集成第三方模型和自有模型;对于自有模型,我们通过modelx项目来存储其模型数据。同时在某些私有化场景下,我们也可以基于modex来导入私有化部署所需的模型。对于第三方的模型,通常我们仅仅存储其模型元数据(模型名字,模型数据的url地址等),但不会储存其模型数据本身,KubeGems 模型商店提供了一个“模型同步器",它实际上是一个简单的 spider,会将HuggingFace的模型列表和其他任务相关信息记录下来,以便KubeGems用户可以在KubeGems中筛选和检索。当然modelx 也是可以存储第三方的模型的,例如我们要将一个优秀的开源模型部署到私有化环境下的时候,也可以将第三方的模型数据导入到modex中。

modelx 是一个基于 OCI 的简单、高性能、可扩展的 ML/DL 模型存储库。
Seldon 项目
出于快速部署任意模型的目的,我们需要一套方案来快速集成主流的模型开发框架,同时还能为模型部署提供一些额外的监控数据,经过一些筛选,我们采用的是SeldonIO这个项目。seldon-core 是一个用于打包、部署、监控和管理数千个生产机器学习模型的 MLOps 框架,它主要支持两个类型的推理组件 Triton和 MLServer。Triton 推理服务器是NVIDIA AI平台的一部分,是一款开源推理服务软件,可帮助标准化模型部署和执行,并在生产中提供快速且可扩展的AI服务。MLServer 是机器学习模型的推理服务器,包括对多个框架、多模型服务等的支持,同时也很容易基于它来开发一个自定义的推理运行时,它由Seldon开发,当前KubeGems集成HuggingFace 就是基于 MLServer 项目。有关更多SeldonIO 和 MLServer的信息可以在其官网找到,所以这儿就不再赘述了。

一点使用心得,seldon-core 的 operator 处理 SeldonDeployment 的时候,是通过硬编码编排内容的方式来提交Resource到 Kubernetes API Server,灵活度还是有点欠缺,例如我们想调整Deployment的updateStrategy的时候,就无从下手。单从部署的角度来看,KubeVela 使用模版的办法才是一个更优雅的办法。瑕不掩瑜,这点小问题不影响它是个不错的项目。
MLServer 项目
MLServer 旨在提供一种简单的方法来通过 REST 和 gRPC 接口开始为机器学习模型提供服务,它实现了 KFServing 的 Predict Protocol V2 协议规范。
本文中,Predict Protocol V2 我们简称其为“V2协议"。 V2 推理协议的目的是提供一种标准化协议来与不同的推理服务器(例如 MLServer、Triton 等)和编排框架(例如 Seldon Core、KServe 等)进行通信。 V2 推理协议的规范定义了 REST 和 gRPC 接口和请求负载数据的格式。

MLServer 核心由两个部分组成,他们分别是编解码器(codecs)和运行时(runtime)
编解码器
MLServer 的编解码器负责将用户的输入转换成兼容 Predict Protocol V2 协议的数据格式,同时也将模型的推理输出按照V2协议进行编码返回。MLServer 实现了对V2协议的数据编码的支持,同时允许用户开发和注册自定义的编解码器。
由于V2协议是一个面向推理服务的协议,并没有对媒体类型进行支持,所以对于要求直接将图片或者音频作为输入的任务来说,就需要开发自定义的编解码器。
其中编解码器又分成两个类型,分别是RequestCodec 和 InputCodec
RequestCodec 会作为整个请求的默认编码器,当payload的input字段中没有提供Content-Type的时候,就会使用默认编码器编解码,InputCodec 则是真正执行编解码的编解码,每个RequestCodec应该有一个默认的InputCodec,当payload的input字段中提供了Content-Type的时候,则会使用指定Content-Type的编解码器对数据进行编解码。
例子:
{
"parameters": {
"content_type": "pd"
},
"inputs": [
{
"name": "First Name",
"datatype": "BYTES",
"parameters": {
"content_type": "str"
},
"shape": [2],
"data": ["Joanne", "Michael"]
},
{
"name": "Age",
"datatype": "INT32",
"shape": [2],
"data": [34, 22]
},
]
}
以MLServer在解码这个请求输入的时候,默认使用PandasCodec对数据decode,返回一个pandas.DataFrame,但是 inputs[1] 指定了Content-Type 为str,那么这个字段将被编码成字符串。以上数据会decode为一个python字典
{
"First Name": ["Joanne", "Michale"],
"Age": pandas.DataFrame([34, 22]),
}
运行时

运行时是MLServer实现推理的核心模块,当前MLServer内置了八个推理运行时,每个推理运行时可以注册自己专有的Content-type对应的InputCodec和RequestCodec。目前已经支持的推理框架如下:
| Framework | Package Name | Implementation Class | Example | Documentation |
|---|---|---|---|---|
| Scikit-Learn | mlserver-sklearn | mlserver_sklearn.SKLearnModel | Scikit-Learn example | MLServer SKLearn |
| XGBoost | mlserver-xgboost | mlserver_xgboost.XGBoostModel | XGBoost example | MLServer XGBoost |
| HuggingFace | mlserver-huggingface | mlserver_huggingface.HuggingFaceRuntime | HuggingFace example | MLServer HuggingFace |
| Spark MLlib | mlserver-mllib | mlserver_mllib.MLlibModel | Coming Soon | MLServer MLlib |
| LightGBM | mlserver-lightgbm | mlserver_lightgbm.LightGBMModel | LightGBM example | MLServer LightGBM |
| Tempo | tempo | tempo.mlserver.InferenceRuntime | Tempo example | github.com/SeldonIO/tempo |
| MLflow | mlserver-mlflow | mlserver_mlflow.MLflowRuntime | MLflow example | MLServer MLflow |
| Alibi-Detect | mlserver-alibi-detect | mlserver_alibi_detect.AlibiDetectRuntime | Alibi-detect example | MLServer Alibi-Detect |
| Alibi-Explain | mlserver-alibi-explain | mlserver_alibi_explain.AlibiExplainRuntime | Coming Soon | MLServer Alibi-Explain |
此外,想要开发一个自定义的推理运行时也十分容易,仅需要继承 mlserver.MLModel, 然后实现 load 和 predict方法即可,常见的编码器MLServer已经提供,大部分可以直接复用,如果有特殊的媒体类型,开发一个自己的Codec也十分简单。这儿以transformers库为例,其推理运行时核心代码可以简化如下:
class MyCustomRuntime(MLModel):
# 加载模型
def load(self) -> bool:
settings = get_settings_from_env()
pp = pipeline(**settings)
self._model = pp
# 执行推理
def predict(self, *args, **kwargs):
prediction = self._model(*args, **kwargs)
return self.serialize(prediction)
在load方法中通过transformers库的pipeline来加载模型,在predict方法中使用模型来执行推理,返回被编码器encode之后的推理结果。
KubeGems 的 OpenMMLab 模型推理运行时就是一个自定义的推理运行时,但是尚未支持完所有任务类型。
部署体验
我们经将HuggingFace的相关元数据存放在了KubeGems模型商店中,快速部署一个模型已经十分方便。用户可以在KubeGems模型商店内根据任务类型找到感兴趣的模型,快速部署到自己的环境中。一图胜千言,可以看接下来这两个例子。
运行 HuggingFace 图片语义分割任务(Image Segmentation)
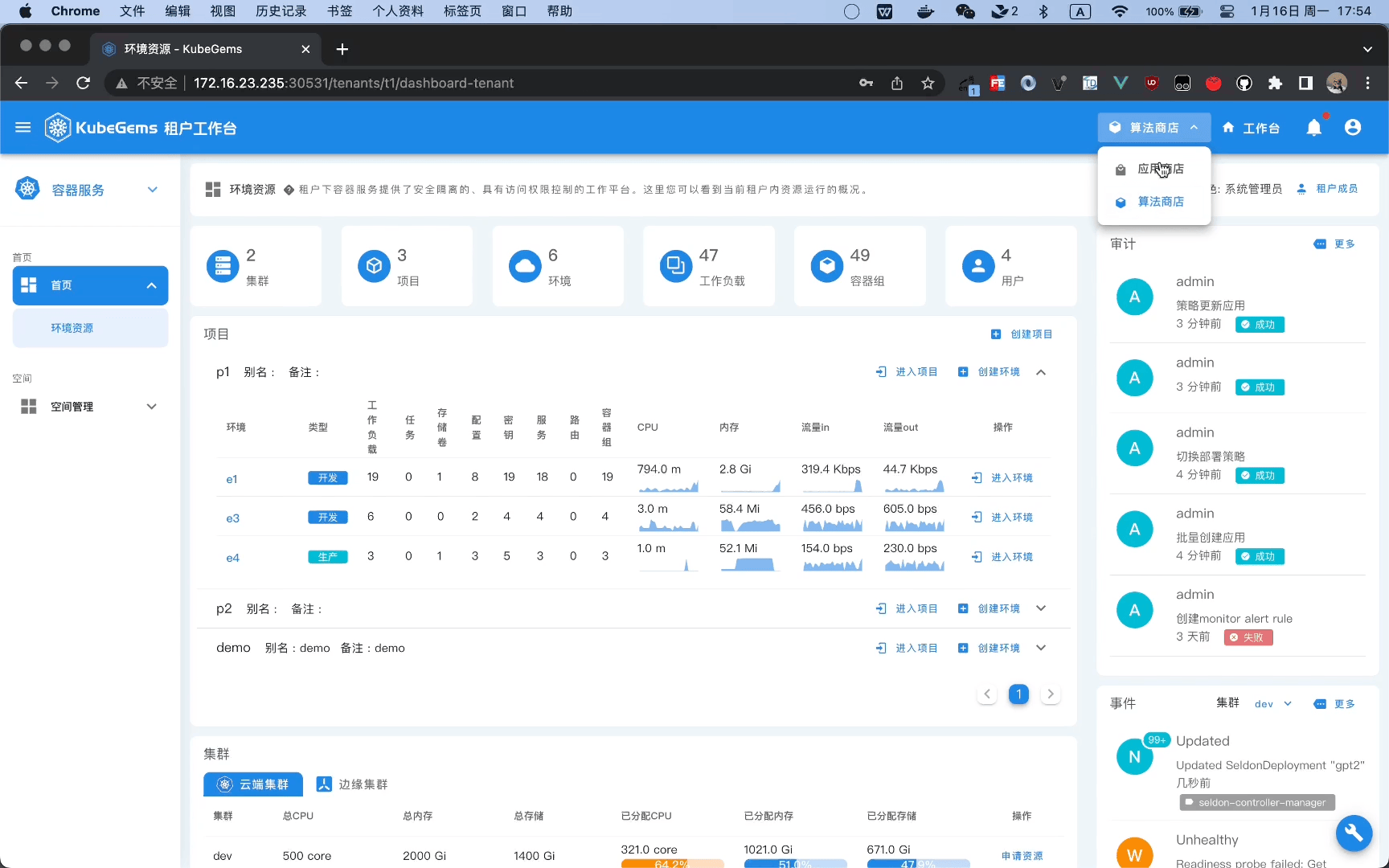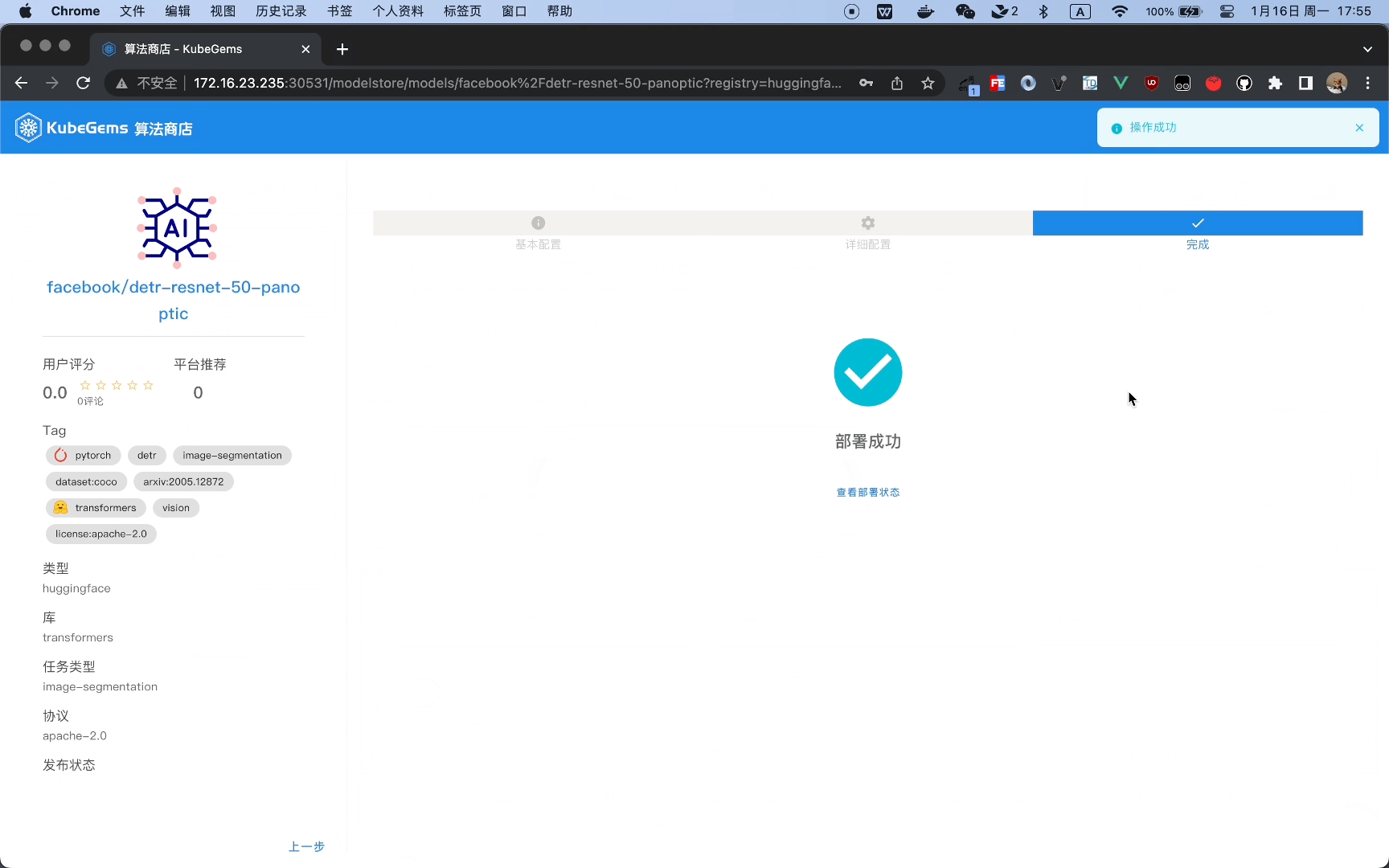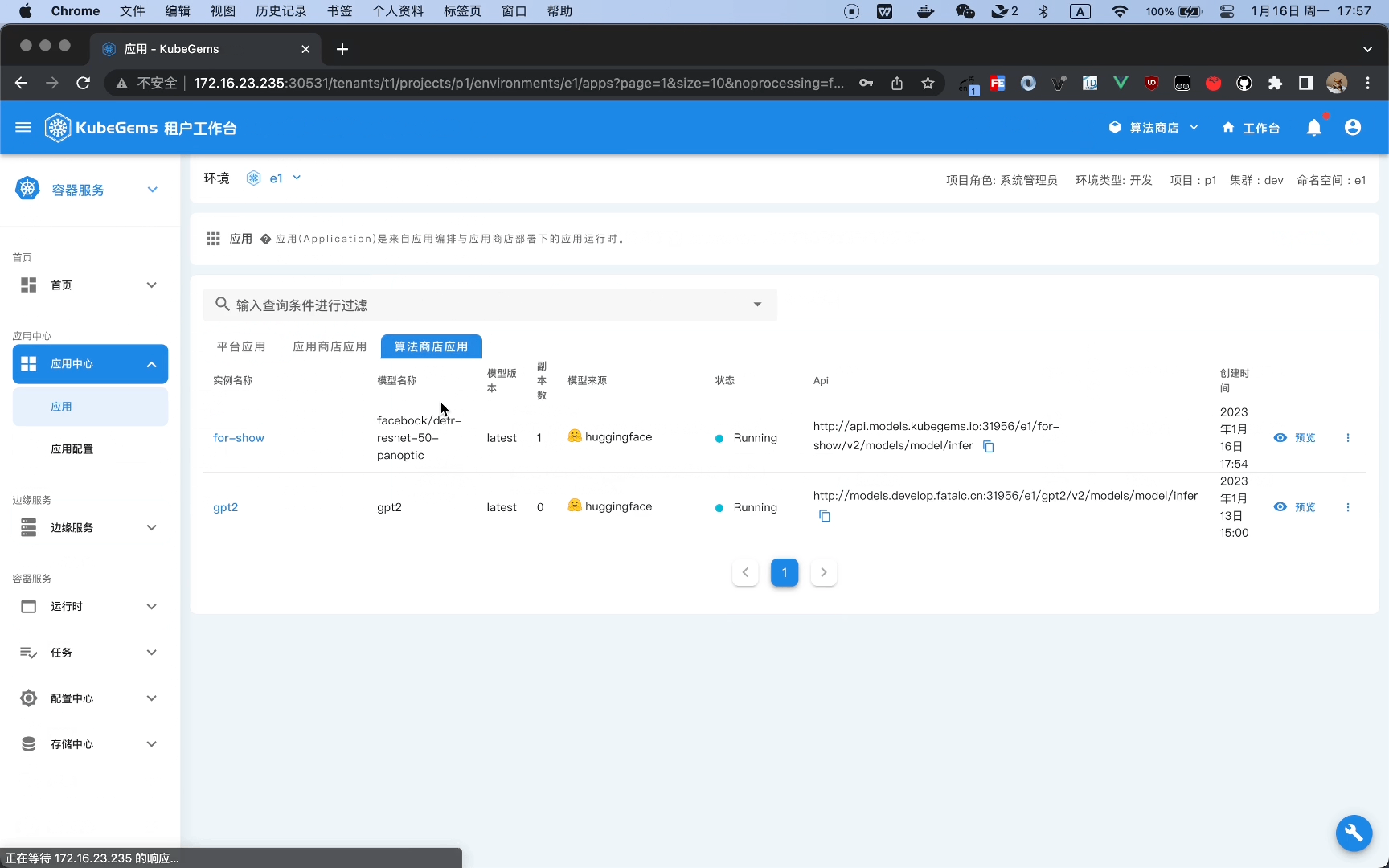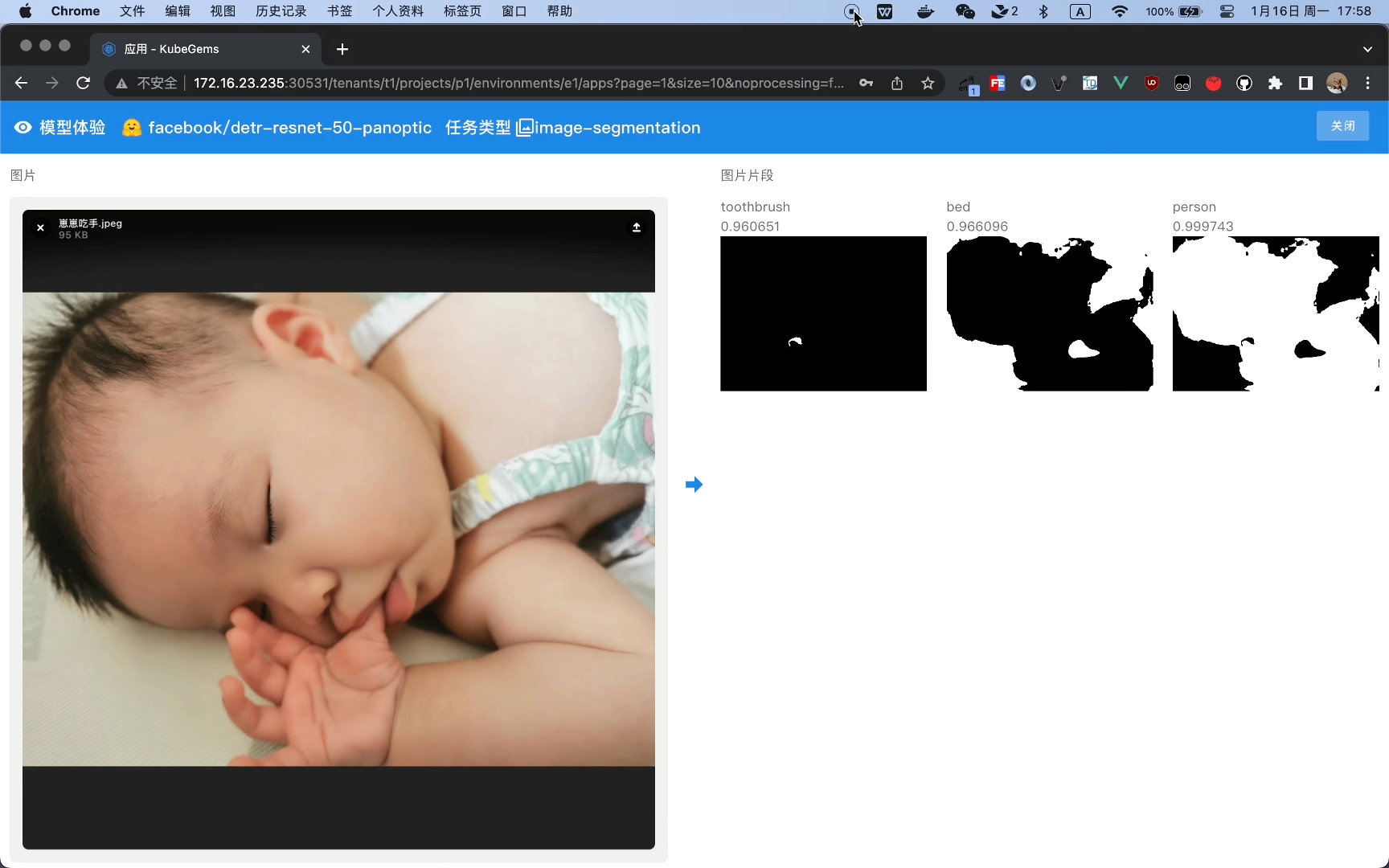
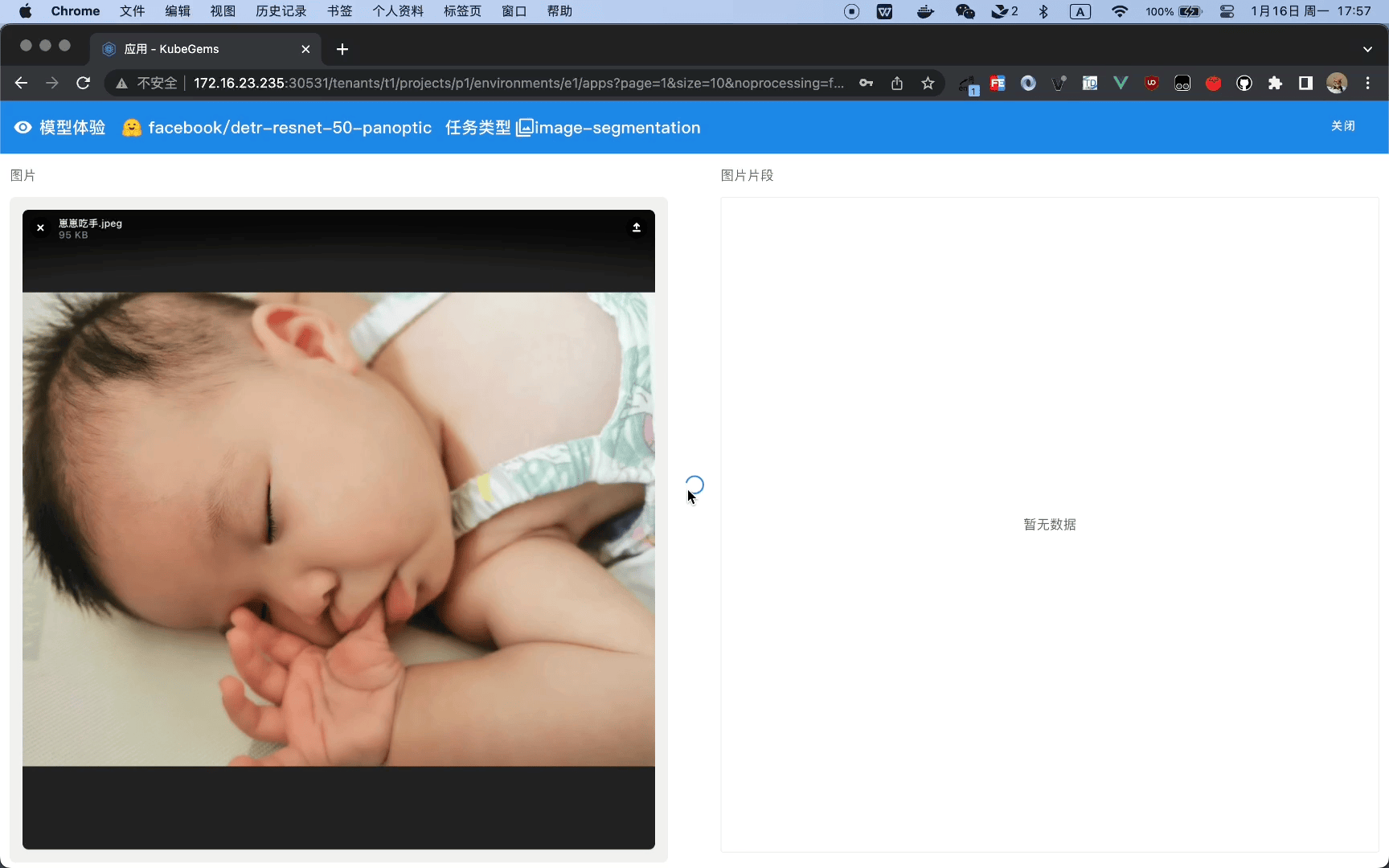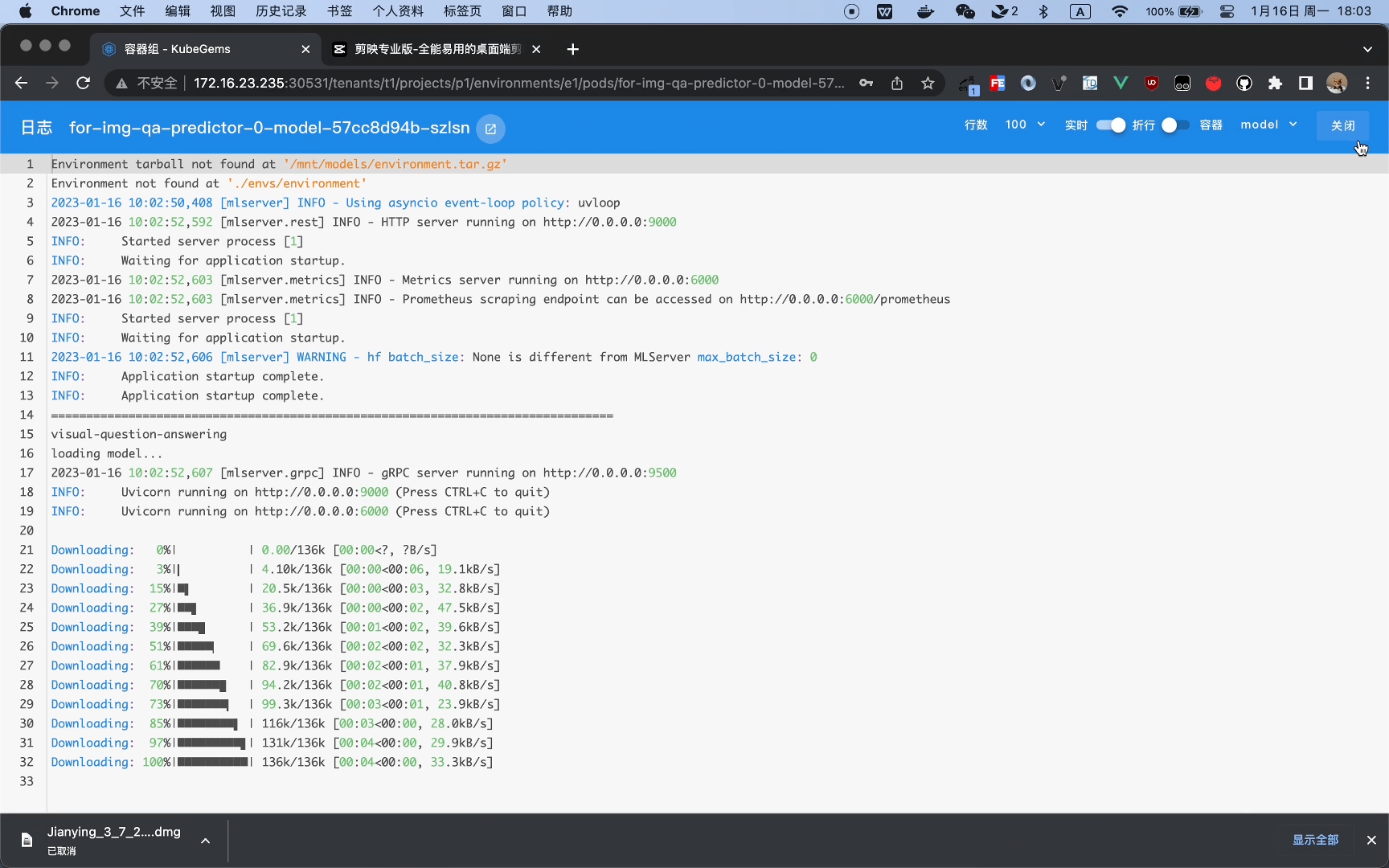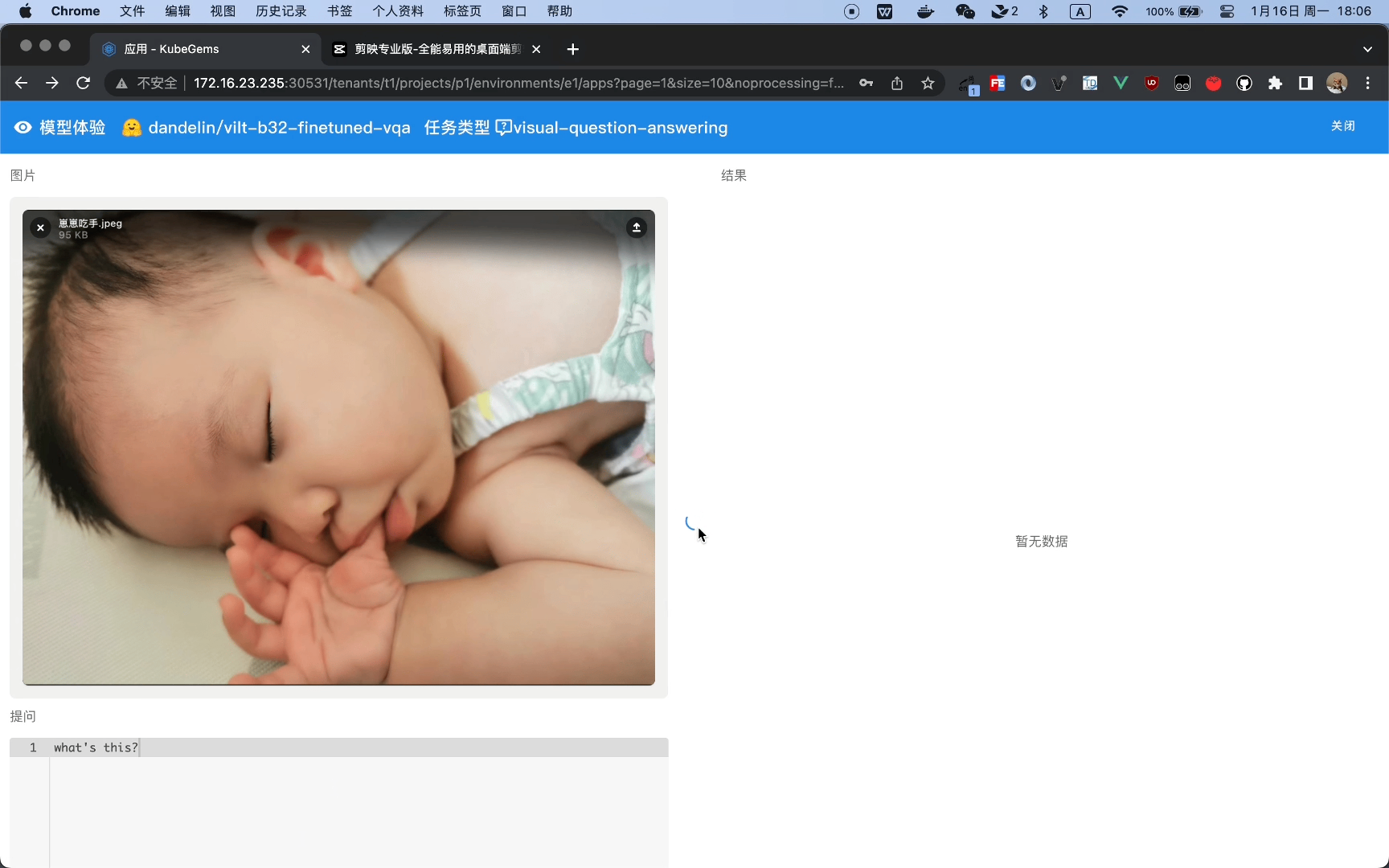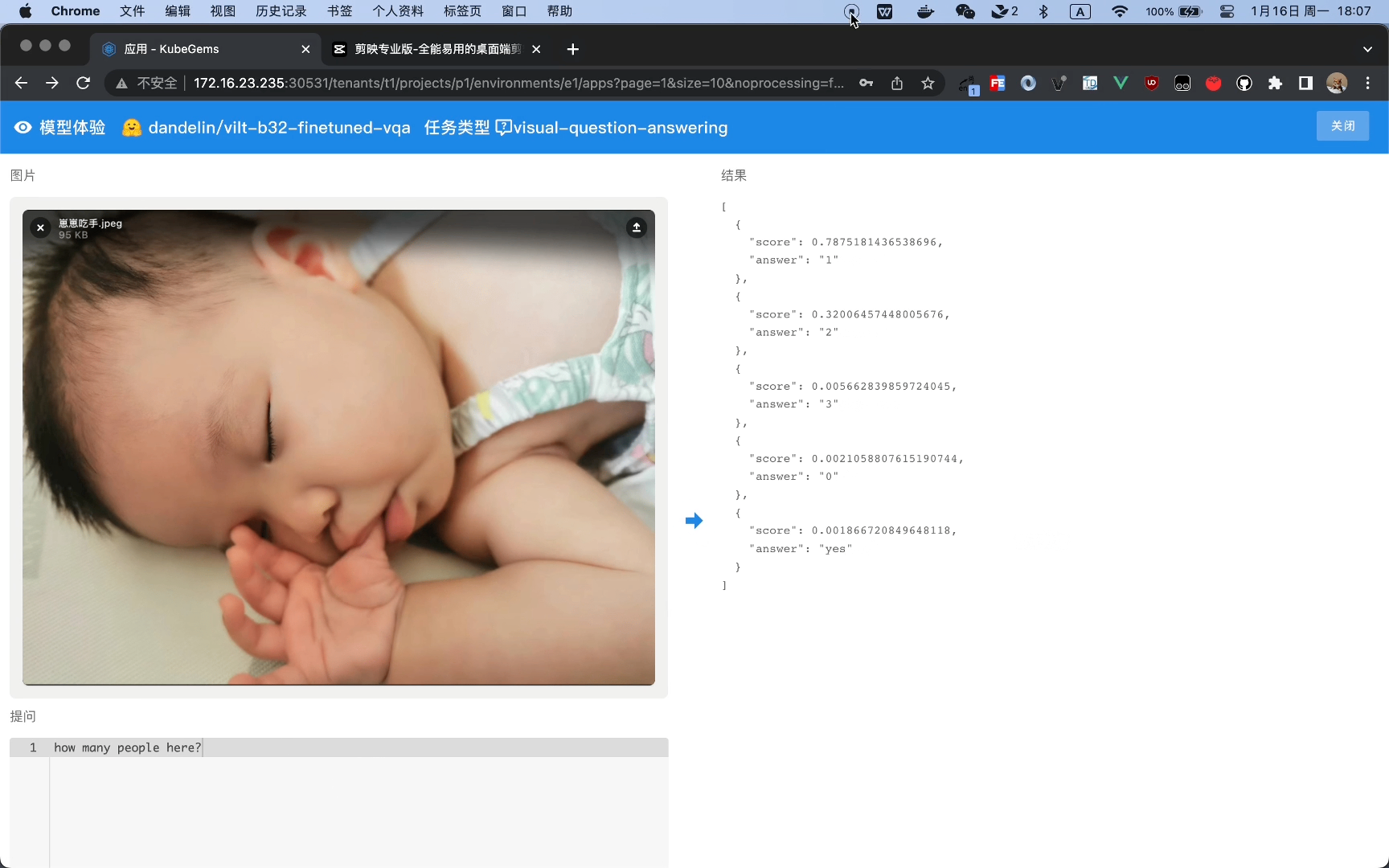
运行HuggingFace 视觉问答任务 (Visual Question Answering)
一些限制和问题
- HuggingFace 并非所有模型都能直接下载,部分模型是需要授权的,这类模型在部署的时候需要提供一个被授权用户的Token,KubeGems仅帮助快速部署和体验模型,使用相关模型的时候还是休要遵守HuggingFace的一些协议,许可,策略等。
- HuggingFace 的模型文件虽然放在了CDN上,但是中国大陆访问的时候,还是会出现下载非常缓慢的情况,特别是十几G以上的大模型。当然,在真实部署的时候,可以通过NFS共享模型卷的方式实现缓存加速,或者实现自己的缓存加速方案,这取决于部署的基础设施情况了,KubeGems 研发团队内部已经完成了一套缓存加速管理方案(这部分并未开源)。
- MLServer 当前并没有提供像openapi schema这样的东西来直接生成接口描述文件,由于其主要支持 Predict Protocol V2 协议,用户只能通过v2协议的metadata来了解输入和输出,这点对于非算法相关背景的同学来说不是很友好。所以我们也在调研其他支持媒体类型的适配器,(如 讯飞的 https://github.com/iflytek/aiges),以尽可能降低使用这些优秀的模型的学习成本和接入的开发成本。